*The word cloud is extracted from the abstract of our research papers.
Research Summary
The rise of the cloud computing paradigm, realized through hyperscale data centers, has rapidly transformed data management infrastructures from centralized databases to distributed systems. Cloud-based systems typically assume trusted infrastructures and tolerate only crash failures. Increasing the number of malicious attacks on the cloud, on one hand, and the rapid popularity of blockchain, on the other hand, have shifted the focus of fault tolerance from tolerating crash failures to tolerating malicious failures, making untrusted infrastructures more prevalent and commonplace for storing data. Tackling practical large-scale problems on untrusted infrastructures requires addressing the natural tension between scalability, fault tolerance, and trustworthiness, which can be made possible through leveraging scalable data management solutions as well as cryptographic and distributed computing approaches developed to restrict malicious behavior.
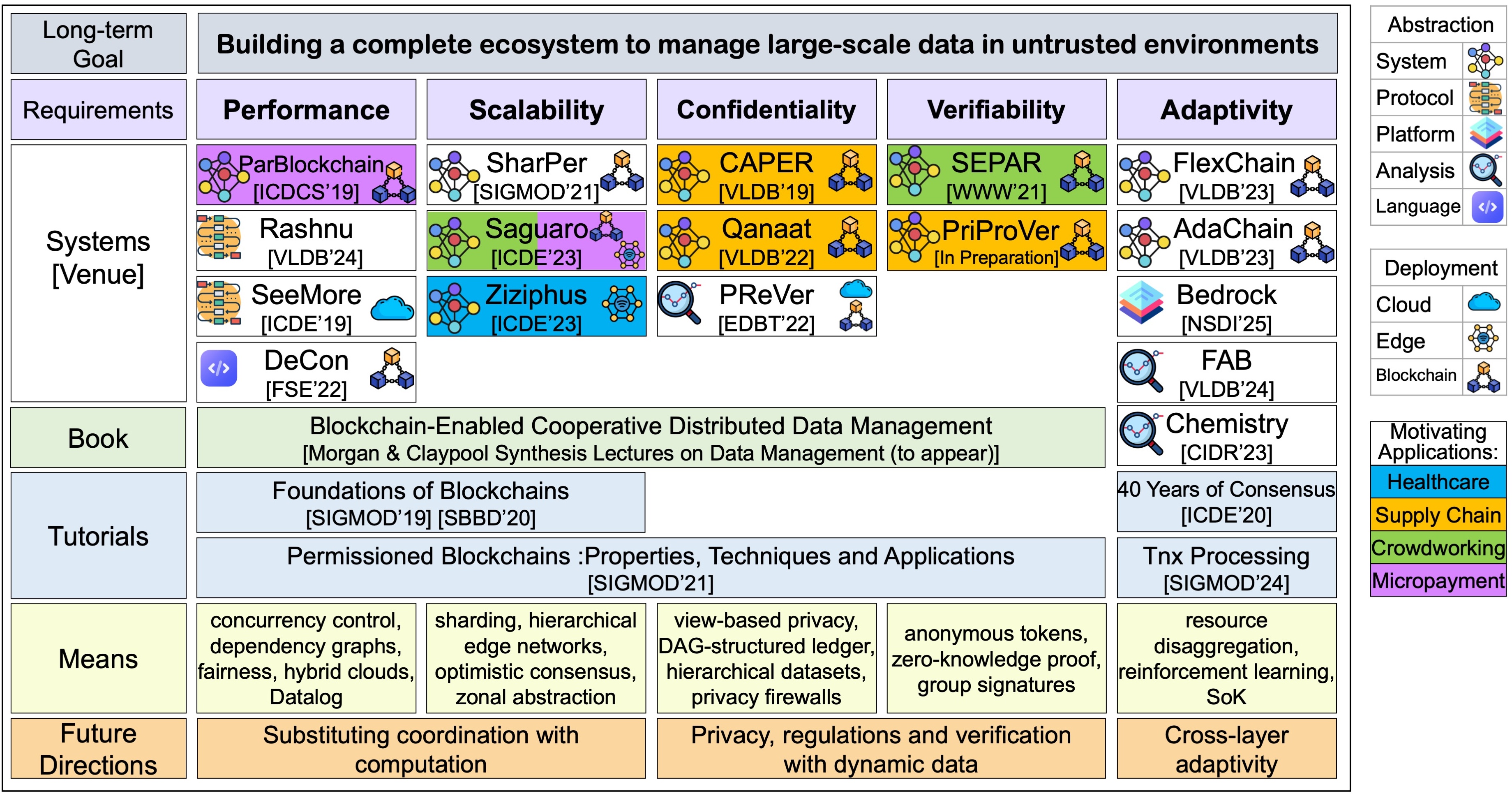
Our research aims to bridge large-scale data management and distributed fault-tolerant systems in the presence of untrustworthy infrastructures. Our long-term goal is to build a complete ecosystem that efficiently manages large-scale data on distributed untrusted infrastructures. Since the current data management systems are mainly built for trusted infrastructures, a significant redesign and reconsideration of the fundamentals and principles of distributed data management are needed. To realize this vision, we study the fundamental distributed data management functionalities, such as transaction processing and consensus. Specifically, the focus of our research, both in my dissertation research [5] and subsequent work, has been on four main directions and associated challenges as follows.
• First, understanding the role of consneuss protoocls and designing effienct consneuss protocols suitable for large-scale data management processing systems [6][17][21][22][23][30]
(Thrust 1).
• Second, designing database-enabled techniques to address performance and scalability requirements of managing large-scale data in untrusted infrastructures
[2][3][10][12][19][20]
(Thrust 2).
• Third, leveraging privacy and cryptography techniques to support confidentiality and verifiability in the context
of cooperative data management
[1][9][13][14][31]
(Thrust 3).
• Fourth, addressing the adaptivity requirement of large-scale systems in all infrastructure, transaction processing,
and consensus layers by relying on resource desegregation and machine learning approaches
[15][16][18][24][26][28][29]
(Thrust 4).
The Figure presents a summary of our research. Next, we discuss the four directions and show how our research addresses them in different systems. Other than the main research papers and software systems, the figure also categorizes our conference tutorials [7][11][8][21][25], and published book [27].
1. Reaching agreement on transaction order: core consensus
The main stages of processing transactions in fault-tolerant systems are order and execution. The order stage uses a consensus protocol to assign an order to a transaction in the global service history, while the execution stage executes the transaction in that order. The first thrust of our research aims to develop more efficient consensus protocols.
1.1. Consensus across heterogeneous clouds. While large enterprises might have their own geo-replicated fault-tolerant cloud storage, smaller enterprises may only have a local private cloud that is lacking in resources to guarantee fault tolerance. The trustworthiness of a private cloud allows an enterprise to build services that can utilize crash fault-tolerant protocols. Nevertheless, due to a lack of private resources, if a third-party public cloud is used, the nodes of the public cloud may behave maliciously, in which case the enterprise is forced to use Byzantine fault-tolerant protocols. To tackle this challenge, we developed SeeMoRe [6], a hybrid consensus protocol that uses the knowledge of where crash and malicious failures may occur in a public/private cloud environment to improve overall performance. SeeMoRe reduces the number of communication phases, and messages exchanged and also requires fewer replicas to tolerate a given number of malicious and crash failures, reducing an application’s overall deployment cost.
1.2. Data-dependent order-fairness. Existing consensus protocols typically rely on a designated leader to receive transactions from clients, assign order to each transaction, and initiate agreement among all replicas. Nevertheless, a malicious leader can control transactions’ inclusion and final ordering without violating safety or liveness. Existing Byzantine fault-tolerant (BFT) protocols either allow the adversarial manipulation of the actual ordering of transactions or incur high performance overhead. We observed that fair ordering is essential when transactions access the same data objects. Based on this observation, we first defined the notion of data-dependent order-fairness to ensure fair ordering of data-dependent transactions and developed a high-performance fair ordering protocol, Rashnu [21]. While Rashnu demonstrated higher performance compared with the state-of-the-art order-fairness protocols, its performance was still limited by its underlying consensus protocol. To address that, we designed another order-fairness protocol, DoD [30] on top of high-performance DAG-based BFT consensus protocols.
1.3. Unified platform for BFT protocols. BFT protocols are different along several dimensions, including the number of replicas, processing strategy (i.e., optimistic, pessimistic, or robust), supporting load balancing, etc. While dependencies and trade-offs among these dimensions lead to several design choices, there is currently no unifying tool that provides the foundations for studying and analyzing BFT protocols’ design dimensions and their trade-offs. We envision that such a unifying foundation will provide an in-depth understanding of existing BFT protocols, highlight the trade-offs among dimensions, and enable protocol designers to choose among several dimensions to find the protocol that best fits the characteristics of their applications. This, however, requires us to extract essential elements of the agreement and define atoms that connect these elements [17]. In an effort to address this challenge, we developed Bedrock [23][22] that can be used to analyze and navigate the evergrowing BFT landscape. Designing such a platform is the first step toward developing an adaptive BFT protocol selection approach.
2. Efficient execution of transactions in scalable systems: performance and scalability
In the second line of work, we first focus on the execution stage of transactions to improve performance. Moreover, partitioning the data into multiple shards that are maintained by different clusters of (crash-only) nodes is a proven approach for improving the scalability of distributed databases. In the presence of Byzantine nodes, however, traditional (coordinator-based) sharding mechanisms are not applicable. The aim of our work in this thrust is to design scalable Byzantine fault-tolerant data management systems.
2.1. Graph-based concurrency control. Traditionally, transactions are executed sequentially to ensure state consistency across all replicas. Sequential execution of transactions, however, limits performance, especially when parallel ordering is not an option due to resource limitations. This is particularly challenging in blockchain systems that are supposed to execute complex compute-intensive smart contracts. In an effort to address this challenge, we designed ParBlockchain [2]. ParBlockchain uses a dependency-graph-based concurrency control mechanism to execute non-conflicting transactions in parallel. ParBlockchain targets blockchain environments and shows significant performance improvement in typical workloads with low to moderate degrees of contention, e.g., 5.7 times higher throughput and 84% less latency compared to the sequential execution paradigm and 2.4 times higher throughput and 87% less latency compared to the state-of-the-art permissioned blockchain system, Hyperledger Fabric.
2.2. Declarative logic of transactions. Finally, to improve the execution stage’s performance, we also focused on the execution logic of transactions. Specifically, we considered smart contracts, programs stored and executed on blockchains, due to their complex logic. The complexity of writing and analyzing smart contracts leads to programs with high execution costs, though avoidable. In this line of work, we focus on designing an easy-to-use declarative programming language, DeCon [12], for implementing smart contracts and specifying contract-level properties. Driven by the observation that smart contract operations and contract-level properties can be naturally expressed as relational constraints, we modeled each smart contract as a set of relational tables that store transaction records. This relational representation of smart contracts enables convenient specification of contract properties, facilitates run-time monitoring of potential property violations, and enables debugging via data provenance. The follow-up work to DeCon has been submitted to the NSF SaTC program as a proposal.
2.3. Flattened sharding. Using the sharding mechanism, different clusters process disjoint sets of transactions in parallel. Sharded systems rely on a coordinator node to process cross-shard transactions, which access multiple shards, using a commitment protocol, e.g., two-phase commit. In the presence of malicious nodes, however, the system cannot rely on a single coordinator, as the coordinator node itself might be malicious. Moreover, relying on a single coordinator (or even a Byzantine fault-tolerant cluster of coordinators) limits the ability of the system to process cross-shard transactions in parallel. To address these challenges, we built a scalable distributed transaction processing protocol, SharPer [10][3]. Unlike traditional single-leader consensus protocols, in SharPer, multiple clusters, each with its own leader, compete with each other to order cross-shard transactions. SharPer processes cross-shard transactions in a flattened manner by running agreements among the nodes of involved shards without requiring a coordinator node. The flattened nature of the cross-shard consensus in SharPer enables parallel processing of transactions with non-overlapping clusters. This setting has been encountered neither in traditional consensus protocols nor in coordinator-based sharded systems, leading us to resolve challenges such as conflicting transactions, deadlock situations, as well as the simultaneous failure of leader nodes across different replicated domains.
2.4. Hierarchical edge networks. SharPer is able to outperform existing scalability solutions by processing cross-shard transactions in parallel without relying on a coordinator node. However, its performance is still inefficient when the system is deployed over wide-area networks, and the involved shards are far apart due to several messages crisscrossing over high-latency low bandwidth links on the Internet. Coordinator-based approaches do not fare much better than the flattened approach of SharPer in such a scenario, as the coordinator node is either close to clients or the data shards, which will not avoid slow network links when cross-shard transactions take place. This is especially important in delay-sensitive edge applications deployed on untrustworthy edge computing infrastructures where establishing consensus among edge servers requires Byzantine fault-tolerant protocols. In edge infrastructures, nodes are placed in a hierarchical structure on the spectrum between edge devices and hyperscale clouds, with edge and fog servers in between. We focus on leveraging the hierarchical structure of edge infrastructures to reduce wide-area communication overhead by localizing network traffic for consensus and replication within local networks. This resulted in Saguaro [19], a scalable system that can process cross-shard transactions in edge networks by relying on the lowest common ancestor of all involved domains. Saguaro also uses the hierarchical structure of edge networks for data aggregation across different shards as well as optimistic processing of cross-shard transactions. The design and development of Saguaro was the focus of our CISE/CNS proposal funded by NSF.
2.5. Confining maliciousness within zones. Scalable geo-distributed systems might also need to enforce network-wide policies on all zones (clusters). In particular, in an edge application, we might want to ensure that a zone cannot host more than 10000 edge devices or that a mobile client can migrate at most 10 times a year. The standard way to ensure this is to maintain global system meta-data on all nodes, including the required data for enforcing policies. However, the global synchronization among all zones in order to update the global system metadata is expensive, as it requires consensus among all zones. To address this challenge, we developed Ziziphus [20], a scalable geodistributed system that supports edge computing applications with mobile edge clients. Ziziphus performs global synchronization using a lightweight Paxos-style protocol among the leader nodes of different zones by confining the maliciousness of Byzantine servers within each zone.
3. Towards collaborative environments: confidentiality and verifiability
Moving towards collaborative environments with multiple enterprises, data confidentiality becomes paramount. In distributed collaborative environments, multiple mutually distrustful enterprises collaborate to provide different services. As a result, we need to address untrustworthiness in both enterprises’ infrastructures and their collaboration. Moreover, In many cross-enterprise environments, participants need to verify transactions that are initiated by other enterprises to ensure the satisfaction of some constraints in a privacy-preserving manner.
3.1 View-based confidentiality. In collaborative environments, the common public data accessed by global transactions across all enterprises, e.g., a place order transaction in a supply chain workflow, must be visible to all enterprises enabling them to verify transactions. However, enterprises want to keep their internal data, which is accessed by internal transactions, confidential. The existing cryptography-based techniques, which prevent the access of irrelevant parties to data, e.g., using encryption, mainly suffer from the computation and communication overhead. We took the first step towards a scalable, confidential cross-enterprise solution by developing Caper [1]. Caper presents a view-based confidentiality technique that maintains different local views of data on different parties while guaranteeing data consistency across views using DAG-structured logs (ledgers). Caper further introduces different consensus protocols to globally order cross-enterprise transactions. Caper processes low-contention workloads with 12 times higher throughput at the same latency compared to Hyperledger Fabric.
3.2. Hierarchical data model. In addition to local and global transactions, any subset of enterprises involved in a collaboration workflow might want to keep their collaboration private from other enterprises. For example, a supplier might want to make private transactions with a manufacturer to keep some terms of trade confidential from other enterprises. Moreover, even if the access of irrelevant parties to confidential data is prevented, an attacker might compromise some nodes within an enterprise’s untrusted infrastructure, resulting in confidential data leakage. We developed Qanaat [13] to address these two challenges. Qanaat proposes a novel hierarchical data model consisting of a set of data collections to support confidential collaboration (i.e., data sharing) among any subset of enterprises. To prevent confidential data leakage despite the Byzantine failure of nodes, Qanaat utilizes the privacy firewall technique and (1) separates ordering nodes that agree on the order of transactions from execution nodes that execute transactions and maintain the ledger and (2) uses privacy filters between execution nodes and ordering nodes.
3.3. Anonymous tokens. Recently, there has been increasing interest by governmental, legal and social institutions to enforce regulations, such as minimal and maximal work hours, on crowdworking platforms. Platforms within multiplatform crowdworking systems, therefore, need to collaborate to enforce cross-platform regulations. For example, the total work hours of a worker, who might work for multiple crowdworking platforms, per week may not exceed 40 hours to follow the Fair Labor Standards Act2 (FLSA). While collaborating to enforce global regulations requires the transparent sharing of information about tasks and their participants, the privacy of all participants needs to be preserved. To address the tension between privacy and transparency in the context of multi-enterprise environments, we developed Separ [9][31]. Separ enforces privacy using lightweight and anonymous tokens, while transparency is achieved using fault-tolerant blockchain ledgers shared among multiple platforms.
3.4. Dynamic data: privacy, regulations and verification. The privacy of stored data and the privacy of querying data at a large scale have been widely studied. However, databases are not solely query engines on static data; they must support updates on dynamically evolving datasets. Moreover, the underlying infrastructure might consist of a single database stored remotely on untrusted providers or multiple independent databases owned by different mutually distrustful enterprises. Furthermore, the updates need to be verified against internal constraints or global regulations before being executed on databases. This opens the space of privacy-preserving data management from the narrow perspective of private queries on static datasets to the larger space of private management of dynamic data. Our goal is to design a universal framework for managing regulated dynamic data in a privacy-preserving manner. In a nutshell, the framework needs to support scalable, efficient, consistent, and verifiable execution of updates on data with regulations while preserving privacy. Designing this framework requires solving multiple challenges. First, the efficient verification of an update with respect to a given generally formulated regulation where the update and the regulation or both might have privacy constraints. Second, the efficient execution of an update on data where the update and the data or both might have privacy constraints. Finally, the scalability of these solutions with respect to the frequency of updates as well as the size of the data. We have taken the first step toward this goal in PReVer [14].
4. Tackling diverse and dynamic workloads: adaptivity
Data management service providers need to guarantee high-throughput services over various transaction workloads. In this line of research, we present different techniques at infrastructure, transaction processing architecture, and the consensus protocol level to deal with diverse and dynamic workloads.
4.1. Resource disaggregation. Transactions might perform memory-intensive operations, compute-intensive operations, or a mix of both at different times and execution stages. These diverse hardware demands require rethinking existing system architectures to enable the flexibility of scaling compute and memory resources independently and elastically. Recently, resource disaggregation has become a trend in data center design. This looming resource disaggregation model will manifest itself by reorganizing resources from servers to physically distinct pools that are dedicated to processing, memory, or storage. To demonstrate the effectiveness of resource disaggregation in addressing the diverse resource requirements of workloads on untrusted infrastructures, we, for the first time, developed a novel disaggregated permissioned blockchain system, FlexChain [15]. FlexChain comprises a tiered key-value store based on disaggregated memory and storage that elastically scales the state.
4.2. Adaptive blockchains using reinforcement learning. Other than the underlying hardware resources, the choice of transaction processing architecture significantly impacts system performance. Distributed systems present significant variations in architectural design, including the sequence in which ordering and execution are performed, the number of transactions in a batch, stream processing (with no batch), and the use of reordering and early aborts. Depending on the workload characteristics, different architectures exhibit various performances. This demonstrates the need for a framework that adaptively chooses the best architecture in order to optimize throughput for dynamic transaction workloads. AdaChain [18] addresses this challenge by automatically adapting to an underlying, dynamically changing workload through the use of reinforcement learning. AdaChain switches from the current architecture to a promising one at runtime in a way that respects correctness and security concerns.
4.3. Making consensus protocols adaptive. While various BFT protocols have been proposed, the performance ranking of BFT protocols varies significantly depending on client workloads, network configurations, and application needs. For example, protocols that reduce message complexity by increasing communication phases exhibit better throughput but worse latency. In addition, adversarial behaviors in the system also affect the best-performing protocol choice. The lack of a clear ``winner'' among BFT protocols makes it difficult for application developers to choose one and may invalidate their choice if workloads or attacks change. This is exacerbated in blockchain systems where application workloads and potential attacks are diverse and dynamic. To address this challenege, we propose BFTBrian [28][26], a reinforcement learning (RL) based BFT system. Given a performance metric to optimize, BFTBrian is able to smartly switches between a set of BFT protocols at run-time under dynamic workloads.
4.4. Full stack adpativity. Studying different transaction processing architectures showed us that depending on workload and hardware characteristics, the performance of a given architecture can vary drastically, hence, there is no one-size-fits-all architecture. In our experiments, we observed that not only is there no dominant architecture, but some architectures that perform well on one workload can perform quite poorly on another. We envision that adaptivity is the main feature of the next generation of transaction processing systems. On one hand, such systems need to support automatically adapting to an underlying, dynamic workload. On the other hand, they need to detect failures and attacks and take appropriate actions against them, e.g., by switching from an optimistic to a pessimistic BFT protocol. Adaptivity needs to be considered at three different levels. First, at the infrastructure level, the system should be able to use compute and memory resources independently and elastically. Second, at the transaction processing level, the system needs to switch between different architectures, and finally, at the consensus level, the system must choose the best protocol among dozens of BFT protocols. Putting all these three components together, an adaptive system must respond to the dynamicity of workloads, failures, and attacks by simultaneously choosing the best hardware, transaction processing architecture, and consensus protocol. This requires leveraging resource disaggregation and reinforcement learning approaches. FAB [24] articulates our vision for a learning-based distributed database deployed in untrustworthy environments.
4.5. Adaptive sharding in untrustworthy environments. A key challenge in scalable data management is developing an optimal data sharding strategy that efficiently allocates data items to various clusters of nodes while balancing competing objectives, such as load balancing, minimizing cross-shard transactions, and optimizing throughput and latency. While traditional partitioning techniques exist, they often lead to a significant number of cross-shard transactions. Unfortunately, current dynamic sharding systems are primarily designed for trusted environments and are unsuitable for Byzantine environments. Marlin [29][16] presents a scalable distributed data management system designed to tolerate Byzantine faults while efficiently adapting to dynamic workloads.
References
[1] M. J. Amiri, D. Agrawal, and A. El Abbadi. CAPER: a cross-application permissioned blockchain. VLDB 2019.[2] M. J. Amiri, D. Agrawal, and A. El Abbadi. ParBlockchain: Leveraging transaction parallelism in permissioned blockchain systems. ICDCS 2019.
[3] M. J. Amiri, D. Agrawal, and A. El Abbadi. On sharding permissioned blockchains. IEEE Blockchain 2019.
[4] S. Maiyya, V. Zakhary, M. J. Amiri, D. Agrawal, and A. El Abbadi. Database and distributed computing foundations of blockchains. SIGMOD 2019.
[5] M. J. Amiri. Large-Scale Data Management using Permissioned Blockchains. PhD Thesis, University of California, Santa Barbara, 2020.
[6] M. J. Amiri, S. Maiyya, D. Agrawal, and A. El Abbadi. SeeMoRe: A fault-tolerant protocol for hybrid cloud environments. ICDE 2020.
[7] M. J. Amiri, D. Agrawal, and A. El Abbadi. Modern large-scale data management systems after 40 years of consensus. ICDE 2020.
[8] M. J. Amiri, S. Maiyya, V. Zakhary, D. Agrawal, and A. El Abbadi. Blockchain system foundations. SBBD 2020.
[9] M. J. Amiri, J. Dugu´ep´eroux, T. Allard, D. Agrawal, and A. El Abbadi. Separ: Towards regulating future of work multi-platform crowdworking environments with privacy guarantees. In Proceedings of The Web Conf. (WWW), pages 1891–1903, 2021.
[10] M. J. Amiri, D. Agrawal, and A. El Abbadi. SharPer: Sharding permissioned blockchains over network clusters. SIGMOD 2021.
[11] M. J. Amiri, D. Agrawal, and A. El Abbadi. Permissioned blockchains: Properties, techniques and applications. SIGMOD 2021.
[12] H. Chen, G. Whitters, M. J. Amiri, Y. Wang, and B. T. Loo. Declarative smart contracts. FSE 2022.
[13] M. J. Amiri, B. T. Loo, D. Agrawal, and A. El Abbadi. Qanaat: A scalable multi-enterprise permissioned blockchain system with confidentiality guarantees. VLDB 2022.
[14] M. J. Amiri, T. Allard, D. Agrawal, and A. El Abbadi. PReVer: Towards private regulated verified data. EDBT 2022.
[15] C. Wu, M. J. Amiri, J. Asch, H. Nagda, Q. Zhang, and B. T. Loo. FlexChain: An elastic disaggregated blockchain. VLDB 2022.
[16] B. Mehta, N. C. A, P. S. Iyer, M. J. Amiri, R. Marcus, and B. T. Loo. Towards Adaptive Fault-Tolerant Sharded Databases. AIDB@VLDB 2023.
[17] S. Gupta, M. J. Amiri, and M. Sadoghi. Chemistry behind agreement. CIDR 2023.
[18] C. Wu, B. Mehta, M. J. Amiri, R. Marcus, and B. T. Loo. AdaChain: A learned adaptive blockchain. VLDB 2023.
[19] M. J. Amiri, Z. Lai, L. Patel, B. T. Loo, E. Lo, and W. Zhou. Saguaro: An edge computing-enabled hierarchical permissioned blockchain. ICDE 2023.
[20] M. J. Amiri, S. Maiyya, D. Shu, D. Agrawal, and A. El Abbadi. Ziziphus: Scalable data management across byzantine edge servers. ICDE 2023.
[21] H. Nagda, S. Pal Singhal, M. J. Amiri, and B. T. Loo. Rashnu: Data-dependent order-fairness. VLDB 2024.
[22] H. Qin, C. Wu, M. J. Amiri, R. Marcus, B. T. Lou. BFTGym: An Interactive Playground for BFT Protocols. VLDB 2024.
[23] M. J. Amiri, C. Wu, D. Agrawal, A. E. Abbadi, B. T. Loo, and M. Sadoghi. The Bedrock of Byzantine fault tolerance: a unified platform for BFT protocols analysis, implementation, and experimentation. NSDI 2024.
[24] C. Wu, M. J. Amiri, H. Qin, B. Mehta, R. Marcus, and B. T. Loo. Towards Full Stack Adaptivity in Permissioned Blockchains. VLDB 2024.
[25] M. J. Amiri, D. Agrawal, A. El Abbadi, and B. T. Lou. Distributed Transaction Processing in Untrusted Environments. SIGMOD 2024.
[26] C. Wu, H. Qin, M. J. Amiri, B. T. Loo, D. Malkhi, R. Marcus. Towards Truly Adaptive Byzantine Fault-Tolerant Consensus. ACM SIGOPS OSR 2024.
[27] M. J. Amiri, D. Agrawal, and A. El Abbadi. Blockchain-Enabled Large-Scale Transaction Management. Springer Synthesis Lectures on Data Management, 2025.
[28] C. Wu, H. Qin, M. J. Amiri, B. T. Lou, D. Malkhi, R. Marcus. BFTBrain: Adaptive BFT Consensus with Reinforcement Learning. NSDI 2025.
[29] B. Mehta, N. Baghel, M. J. Amiri, B. T. Lou, R. Marcus. Adaptive Sharding in Untrusted Environments. SIGMOD 2026.
[30] H. Nagda, S. Sankhe, S. Sinha, K. Attarha, M. J. Amiri, B. T. Lou. DAG of DAGs: Order-Fairness Made Practical. SIGMOD 2026.
[31] M. J. Amiri, T. Allard, D. Agrawal, A. El Abbadi, B. T. Lou. Privacy Meets Regulations: Shaping the Future of Work. CIDR 2026.