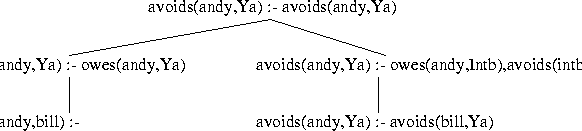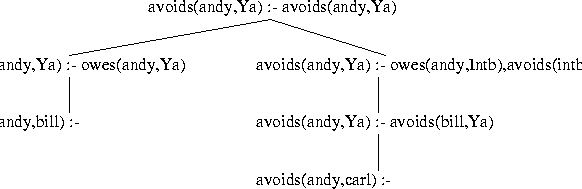We understood a Prolog evaluation as a set of executing deterministic procedural machines, increasing in number as one of them executes a multiply-defined procedure, and decreasing in number as one of them encounters failure. Then we saw how it was implemented by means of a depth-first backtracking search through the tree of SLD computations, or procedure evaluations. To add the concept of tabling, we have to extend our computational model. Tabling execution is best understood as computation in a concurrent programming language. Nontabled predicates are evaluated exactly as in SLD, with the intuition of a procedure call. Evaluating a tabled predicate is understood as sending the goal to a cacheing goal server and then waiting for it to send back the answers. If no server for the goal exists, then one is created and begins (concurrently) to compute and save answers. If a server for this goal already exists, none needs to be started. When answers become available, they can be (and eventually will be) sent back to all waiting requesters. So tabled predicates are processed ``asynchronously'', by servers that are created on demand and then stay around forever. On creation, they compute and save their answers (eliminating duplicates), which they then will send to anyone who requests them (including, of course, the initiating requester.)
Now we can see tabled execution as organized around a set of servers. Each server evaluates a nondeterministic procedural program (by a depth-first backtracking search through the alternatives) and interacts with other servers asynchronously by requesting answers and waiting for them to be returned. For each answer returned from a server, computation continues with that alternative.
The abstraction of Prolog computation was the SLD tree, a tree that showed the alternative procedural machines. We can extend that abstraction to tabled Prolog execution by using multiple SLD trees, one for each goal server.
Let's trace the execution of the program for reachability on the
simple graph in owes/2, given the query :- avoids(andy,Ya). Again, we start with a query and develop the SLD
tree for it until we hit a call to a tabled predicate. This is shown
in Figure
3.1.
ans to
collect the answers, for SLD trees for goal servers, we will use the
entire goal to save the answer, so the left-hand-side of the root of
the SLD tree is the same as the right-hand-side. Computation traces
this tree in a left-to-right depth-first manner.
So the initial global machine state, or configuration, is:
avoids(andy,Ya) :- avoids(andy,Ya).
Then rules are found which match the first goal on the right-hand-side of the rule. In this case there are two, which when used to replace the expanded literal, yield two children nodes:
avoids(andy,Ya) :- owes(andy,Ya). avoids(andy,Ya) :- owes(andy,Intb),avoids(Intb,Ya).
Computation continues by taking the first one and expanding it. Its selected goal (the first on the right-hand side) matches one rule (in this case a fact) which, after replacing the selected goal with the (empty) rule body, yields:
avoids(andy,bill) :-And since the body is empty, this is an answer to the original query, and the system could print out
Y=bill as an answer.
Then computation continues by using the stack to find that the second child of the root node:
avoids(andy,Ya) :- owes(andy,Intb),avoids(Intb,Ya).should be expanded next. The selected goal matches with the fact
owes(andy,bill) and expanding with this results in:
avoids(andy,Ya) :- avoids(bill,Ya).
Now the selected goal for this node is avoids(bill,Ya), and
avoids is a tabled predicate. Therefore this goal is to be
solved by communicating with its server. Since the server for that
goal does not exist, the system creates it, and schedules it to
compute its answers. This computation is shown in Figure
3.2.
This computation sequence for the goal avoid(bill,Y) is very
similar to the previous one for avoid(andy,Y). The first
clause for avoids is matched, followed by the one fact for
owes that has bill as its first field, which generates
the left-most leaf of the tree of the figure. This is an answer which
this (concurrently executing) server could immediately send back to
the requesting node in Figure 3.1. Alternatively,
computation could continue in this server to finish the tree pictured
in Figure 3.2, finally generating the right-most leaf:
avoids(bill,Ya) :- avoids(carl,Ya)Now since the selected goal here is tabled, the server for it is queried and its response is awaited. Again, there is no server for this goal yet, so the system creates one and has it compute its answers. This computation is shown in Figure 3.3.
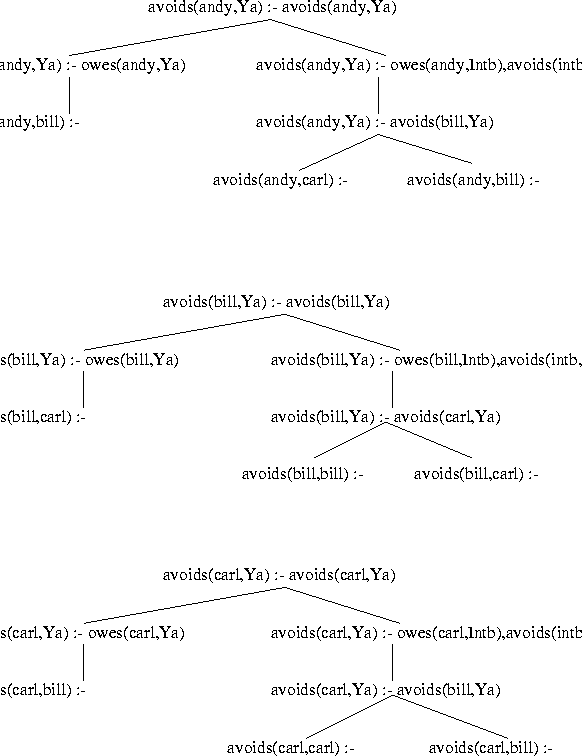
This computaton is beginning to look familiar; again the form of the
computation tree is the same (because only one clause matches
owes(carl,Y)). Again an answer, avoids(carl,bill), is
produced (and is scheduled to be returned to its requester) and
computation continues to the right-most leaf of the tree with the
selected goal of avoids(bill,Ya). This is a tabled goal and so
will be processed by its server. But now the server does exist;
it is the one Figure 3.2. Now we can continue and see
what happens when answers are returned from servers to requesters.
Note that exactly when these answers are returned is determined
by the scheduling strategy of our underlying concurrent language. We
have thus far assumed that the scheduler schedules work for new
servers before scheduling the returning of answers. Other
alternatives are certainly possible.
Now in our computation there are answers computed by servers that need
to be sent back to their requesters. The server for
avoids(bill,Ya) (in Figure 3.2) has computed an
answer avoids(bill,carl), which it sends back to the server for
avoids(andy,Ya) (in Figure 3.1). That adds a child
to the rightmost leaf of the server's tree, producing the new tree
shown in Figure 3.4.
avoids(bill,carl)) has been matched with the
selected goal (avoids(bill,Ya)) giving a value to Ya,
and generating the child avoids(andy,carl) :-. Note that this
child is a new answer for this server.
Computation continues with answers being returned from servers to
requesters until all answers have been sent back. Then there is
nothing left to do, and computation terminates. The trees of the
three servers in the final state are shown in Figure 3.5.
Let's be more precise and look at the operations that are used to construct these server trees. We saw that the SLD trees of Prolog execution could be described by giving a single rule, PROGRAM CLAUSE RESOLUTION, and applying it over and over again to an initial node derived from the query. A similar thing can be done to generate sets of server trees that represent the computation of tabled evaluation. For this we need three rules:
So for example the trees in Figure 3.5 are constructed by
applying these rules to the initial tree (root) for the starting goal.
XSB can be understood as efficiently constructing this forest of
trees. We have seen that XSB with tabling will terminate on a query
and program for which Prolog will loop infinitely. It turns out that
this is not just an accident, but happens for many, many programs.
For example, here we've written the transitive closure of owes using a
right recursive rule, i.e., the recursive call to avoids
follows the call to owes in the second rule defining
avoids. We could also define avoids with a rule that
has a call to avoids before a call to owes. That
definition would not terminate in Prolog for any graph, but with
tabling, it is easily evaluated correctly.