
Face Editing
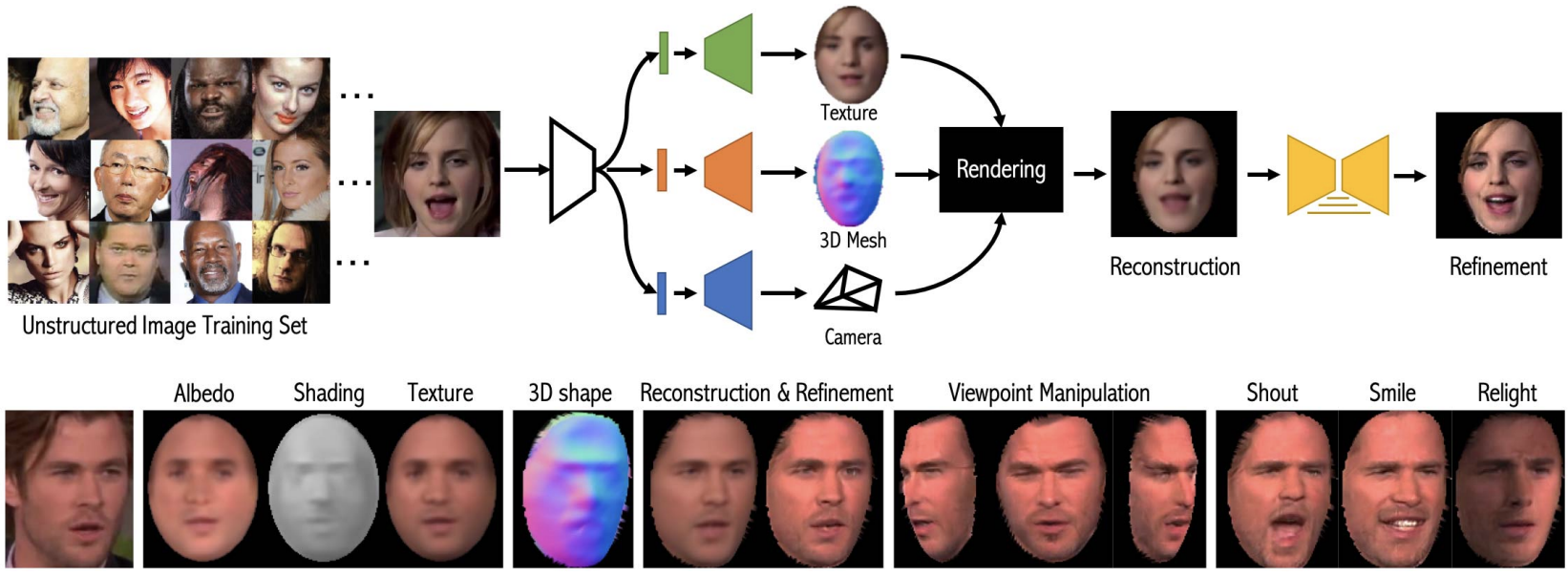
In this work we introduce Lifting Autoencoders, a generative 3D surface-based model of object categories. We bring together ideas from non-rigid structure from motion, image formation, and morphable models to learn a controllable, geometric model of 3D categories in an entirely unsupervised manner from an unstructured set of images. We exploit the 3D geometric nature of our model and use normal information to disentangle appearance into illumination, shading, and albedo. We further use weak supervision to disentangle the non-rigid shape variability of human faces into identity and expression. We combine the 3D representation with a differentiable renderer to generate RGB images and append an adversarially trained refinement network to obtain sharp, photorealistic image reconstruction results. The learned generative model can be controlled in terms of interpretable geometry and appearance factors, allowing us to perform photorealistic image manipulation of identity, expression, 3D pose, and illumination properties.
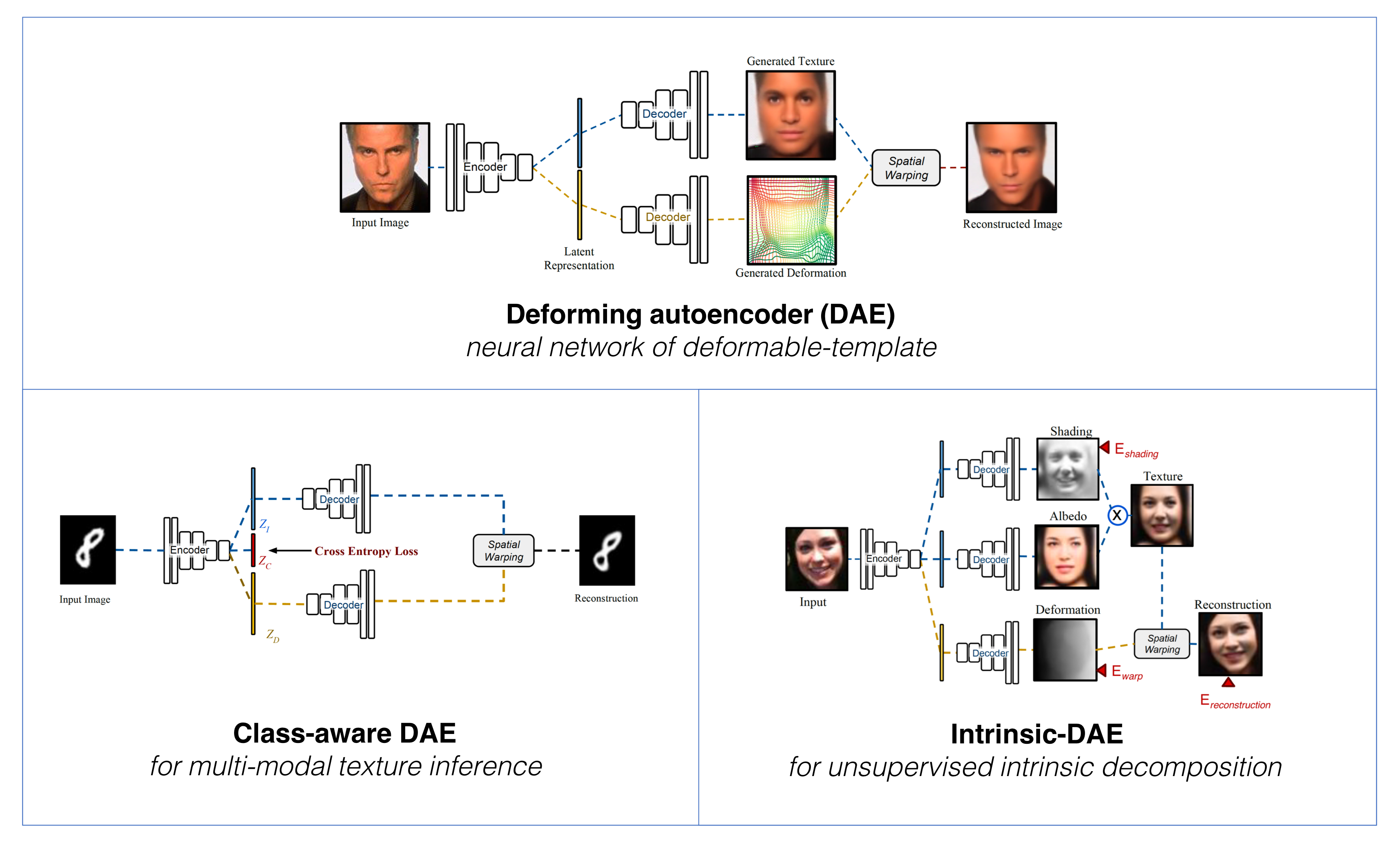
In this work we introduce Deforming Autoencoders, a generative model for images that disentangles shape from appearance in an unsupervised manner. As in the deformable template paradigm, shape is represented as a deformation between a canonical coordinate system (`template') and an observed image, while appearance is modeled in deformation-invariant, template coordinates. We introduce novel techniques that allow this approach to be deployed in the setting of autoencoders and show that this method can be used for unsupervised group-wise image alignment. We show experiments with expression morphing in humans, hands, and digits, face manipulation, such as shape and appearance interpolation, as well as unsupervised landmark localization. We also achieve a more powerful form of unsupervised disentangling in template coordinates, that successfully decomposes face images into shading and albedo, allowing us to further manipulate face images.