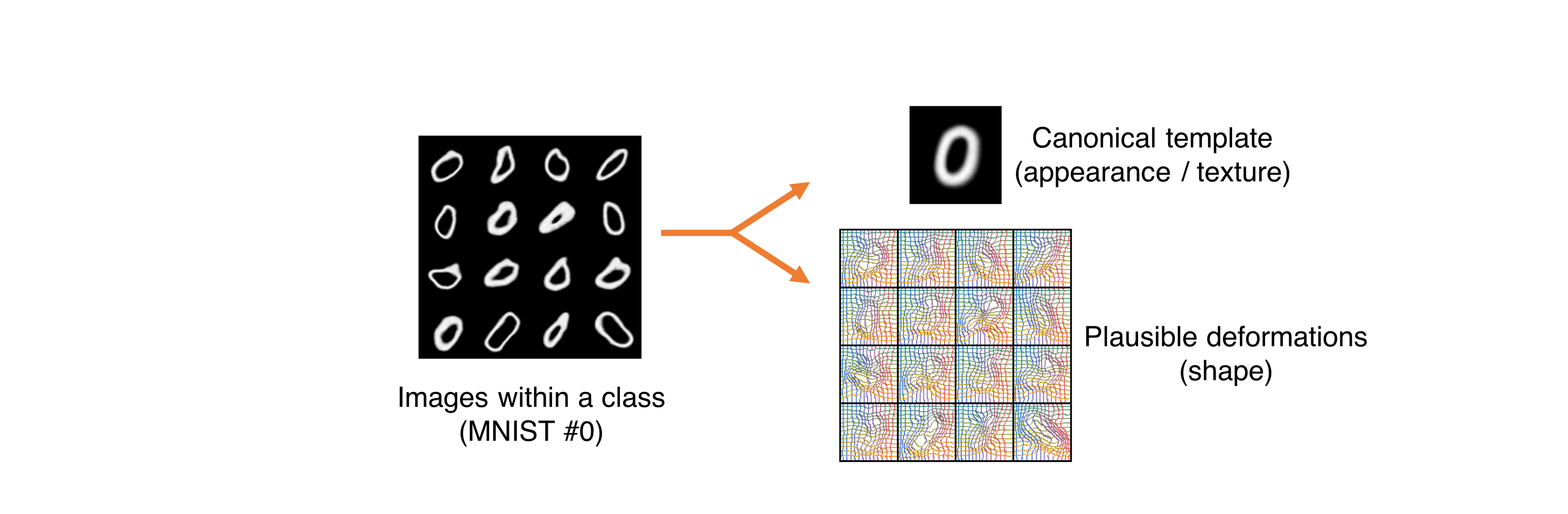
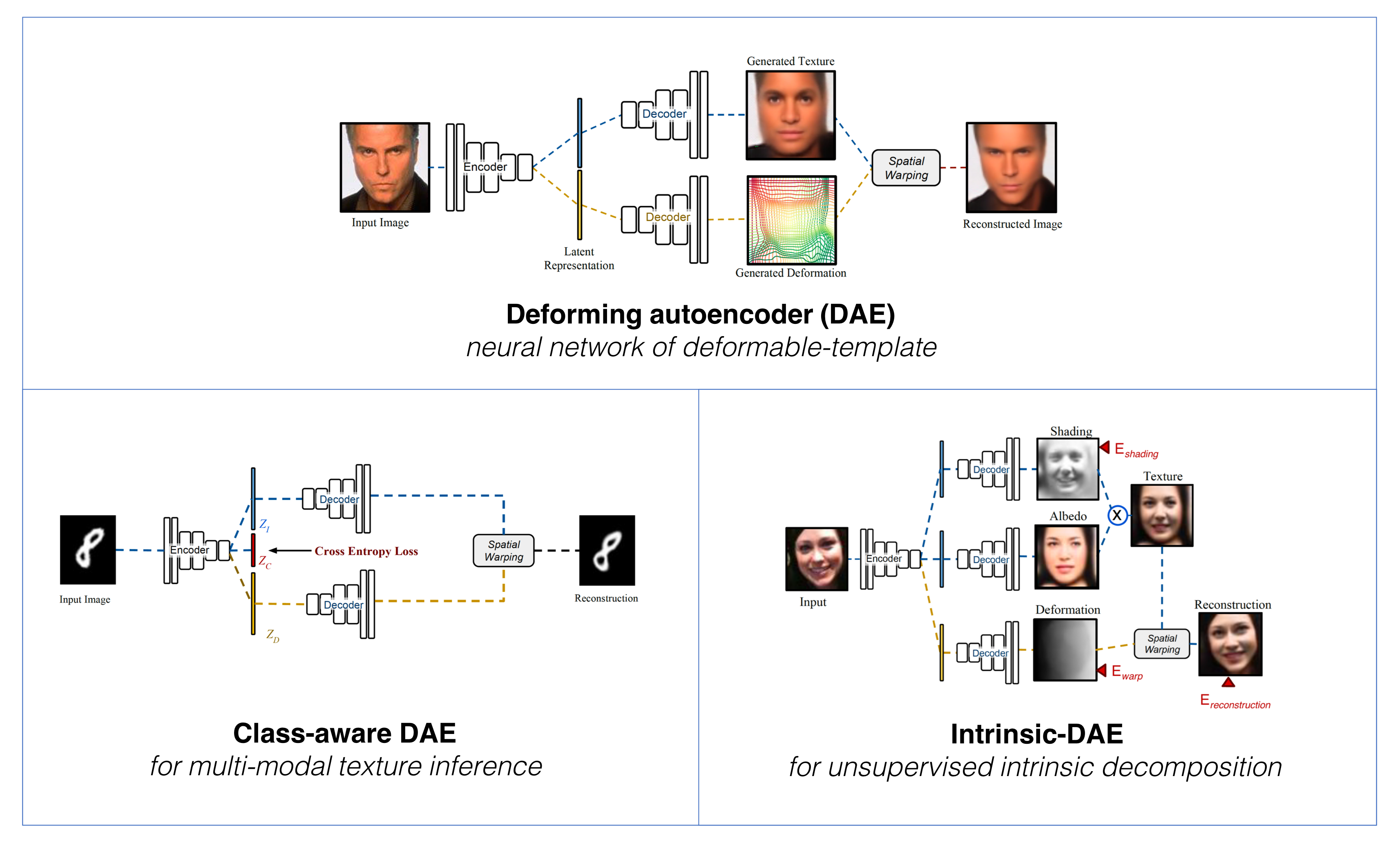
In this work we introduce Deforming Autoencoders, a generative model for images that disentangles shape from appearance in an unsupervised manner. As in the deformable template paradigm, shape is represented as a deformation between a canonical coordinate system (`template') and an observed image, while appearance is modeled in deformation-invariant, template coordinates. We introduce novel techniques that allow this approach to be deployed in the setting of autoencoders and show that this method can be used for unsupervised group-wise image alignment. We show experiments with expression morphing in humans, hands, and digits, face manipulation, such as shape and appearance interpolation, as well as unsupervised landmark localization. We also achieve a more powerful form of unsupervised disentangling in template coordinates, that successfully decomposes face images into shading and albedo, allowing us to further manipulate face images.
If using the code, please cite:
Deforming Autoencoders: Unsupervised Disentangling of Shape and Appearance, Zhixin Shu, Mihir Sahasrabudhe, Riza Alp Guler, Dimitris Samaras, Nikos Paragios, and Iasonas Kokkinos. European Conference on Computer Vision (ECCV), 2018 [
BibTex ]
This work was supported by a gift from Adobe, NSF grants CNS-1718014 and DMS 1737876, the Partner University Fund, and the SUNY2020 Infrastructure Transportation Security Center. Rıza Alp Güler was supported by the European Horizons 2020 grant no 643666 (I-Support).