Datasets

We present LaSOT, a high-quality Large-scale Single Object Tracking benchmark. LaSOT contains a diverse selection of 85 object classes, and offers 1,550 totaling more than 3.87 million frames. The average video length is around 2,500 frames (i.e., around 83 seconds). Each frame in a sequence is carefully and manually annotated with a bounding box. This makes LaSOT, to our knowledge, the largest densely annotated tracking benchmark. Please consider citing our papers if you use LaSOT for your research.
[1] H. Fan, H. Bai, L. Lin, F. Yang, P. Chu, G. Deng, S. Yu, Harshit, M. Huang, J Liu, Y. Xu, C. Liao, L Yuan, and H. Ling. LaSOT: A High-quality Large-scale Single Object Tracking Benchmark, arXiv:2009.03465, 2020.
[2] H. Fan, L. Lin, F. Yang, P. Chu, G. Deng, S. Yu, H. Bai, Y. Xu, C. Liao, and H. Ling. LaSOT: A High-quality Benchmark for Large-scale Single Object Tracking, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
[1] H. Fan, H. Bai, L. Lin, F. Yang, P. Chu, G. Deng, S. Yu, Harshit, M. Huang, J Liu, Y. Xu, C. Liao, L Yuan, and H. Ling. LaSOT: A High-quality Large-scale Single Object Tracking Benchmark, arXiv:2009.03465, 2020.
[2] H. Fan, L. Lin, F. Yang, P. Chu, G. Deng, S. Yu, H. Bai, Y. Xu, C. Liao, and H. Ling. LaSOT: A High-quality Benchmark for Large-scale Single Object Tracking, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
We collected a multi-label dataset of 2078 image patches of nuclei. Image patches are extracted from TCGA glioma pathology whole slide images. Each image patch has 15 binary labels such as "Perinuclear Halos", "Gemistocyte", "Oval", etc. The train/val/test separation schemes are also included in this dataset. Please cite our paper:
@inproceedings{Murthy_WACV17,
Author = {V. Murthy, L. Hou, D. Samaras, T.M. Kurc, J.H. Saltz},
Booktitle = {Winter Conference on Applications of Computer Vision},
Title = {Center-Focusing Multi-task CNN with Injected Features for Classification of Glioma Nuclear Images},
Year = {2017}}
@inproceedings{Murthy_WACV17,
Author = {V. Murthy, L. Hou, D. Samaras, T.M. Kurc, J.H. Saltz},
Booktitle = {Winter Conference on Applications of Computer Vision},
Title = {Center-Focusing Multi-task CNN with Injected Features for Classification of Glioma Nuclear Images},
Year = {2017}}
We collected a dataset of 1785 histopathology image patches. Each patch has a binary label indicating whether the object in the center is a lymphocyte (or a plasma cell) or non-lymphocyte.
If you use this dataset, please cite our papers:
@inproceedings{Hou_PR18,
Author = {L. Hou, V. Nguyen, A.B. Kanevsky, D. Samaras, T.M. Kurc, T. Zhao, R.R. Gupta, Y. Gao, W. Chen, D. Foran, J.H. Saltz},
Booktitle = {Pattern Recognition},
Title = {Sparse Autoencoder for Unsupervised Nucleus Detection and Representation in Histopathology Images},
Year = {2018}}
If you use this dataset, please cite our papers:
@inproceedings{Hou_PR18,
Author = {L. Hou, V. Nguyen, A.B. Kanevsky, D. Samaras, T.M. Kurc, T. Zhao, R.R. Gupta, Y. Gao, W. Chen, D. Foran, J.H. Saltz},
Booktitle = {Pattern Recognition},
Title = {Sparse Autoencoder for Unsupervised Nucleus Detection and Representation in Histopathology Images},
Year = {2018}}

We collected about 700K images in 70K street segments from Google Street View for pavement condition assessment. The images are from NYC and the condition annotation is from NYC Open Data website.
Project page
Project page

We collected around 5 thousand images containing shadows from a wide variety of scenes and photo types. Annotations in the form of shadow binary masks are provided along with the actual images. The shadow label annotations for the 4K images in the training set are the result of applying our proposed label recovery method to reduce label noise. Whereas, the testing images were carefully annotated manually to produce precise shadow masks.
If you use this dataset, please cite our papers:
@inproceedings{Vicente-etal-ECCV16,
Author = {Tomas F. Yago Vicente and Le Hou and Chen-Ping Yu and Minh Hoai and Dimitris Samaras},
Booktitle = {Proceedings of European Conference on Computer Vision},
Title = {Large-scale Training of Shadow Detectors with Noisily-Annotated Shadow Examples},
Year = {2016}}
@inproceedings{yago16, author={Yago Vicente, Tom\'as F. and Hoai, M.H. and Samaras, Dimitris}, booktitle= {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, title={Noisy Label Recovery for Shadow Detection in Unfamiliar Domains}, year={2016}, }
Download
If you use this dataset, please cite our papers:
@inproceedings{Vicente-etal-ECCV16,
Author = {Tomas F. Yago Vicente and Le Hou and Chen-Ping Yu and Minh Hoai and Dimitris Samaras},
Booktitle = {Proceedings of European Conference on Computer Vision},
Title = {Large-scale Training of Shadow Detectors with Noisily-Annotated Shadow Examples},
Year = {2016}}
@inproceedings{yago16, author={Yago Vicente, Tom\'as F. and Hoai, M.H. and Samaras, Dimitris}, booktitle= {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, title={Noisy Label Recovery for Shadow Detection in Unfamiliar Domains}, year={2016}, }
Download
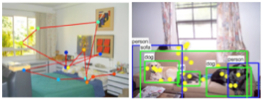
Eye movements and image descriptions were collected on 1,000 images from the PASCAL VOC dataset and 104 images from the SUN09 dataset (183.2MB). It also includes 20 object detectors for the PASCAL and 22 object detectors for the SUN09.
Project page
Project page


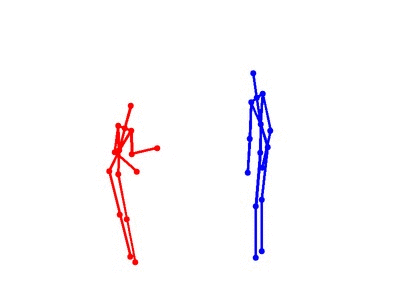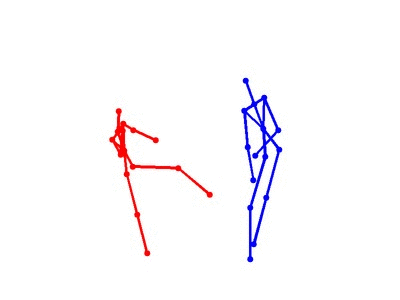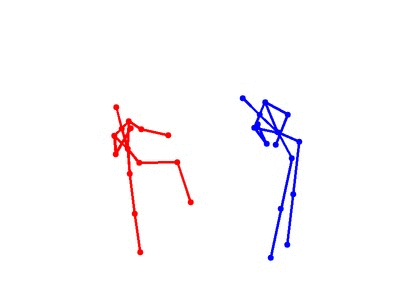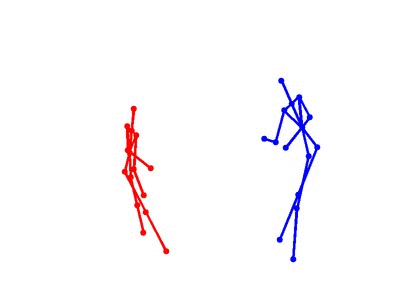


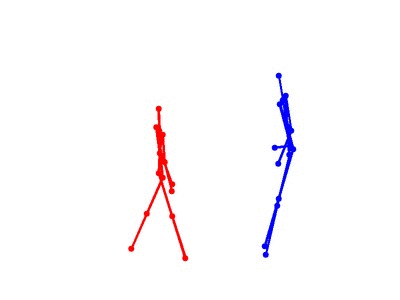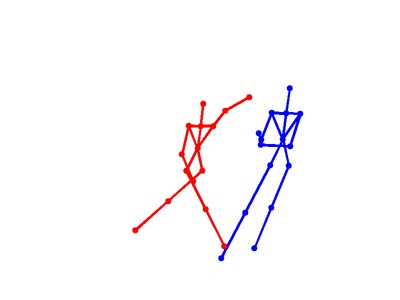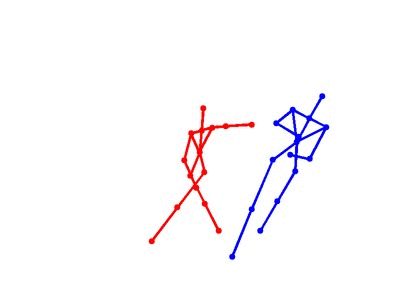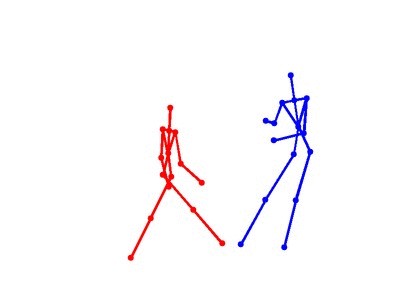


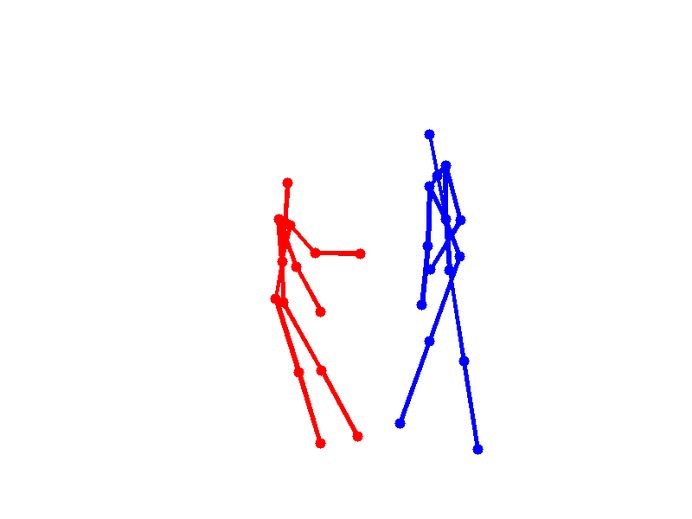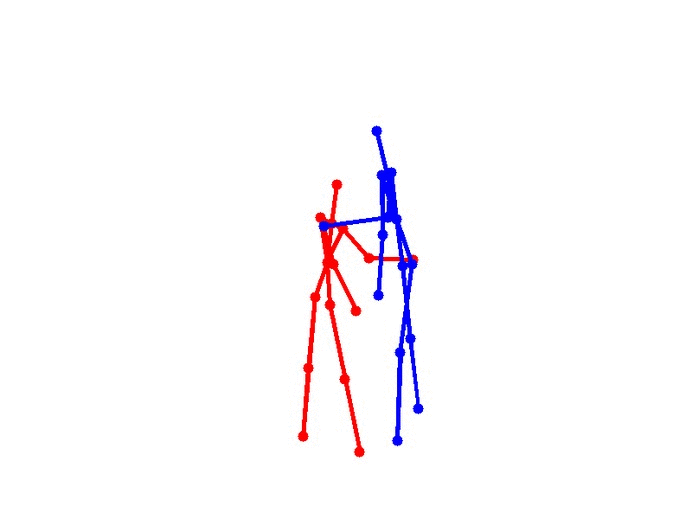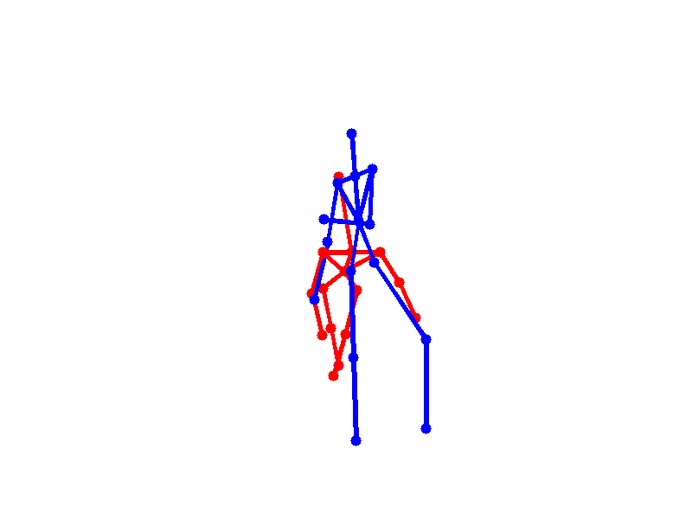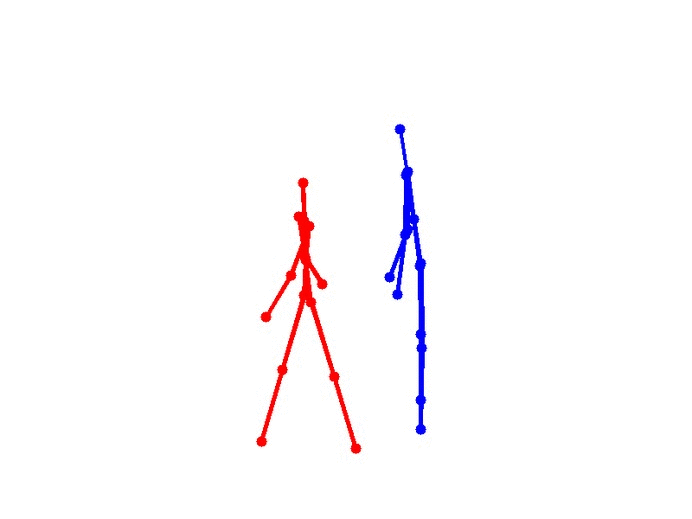
Eight types of two-person interactions were collected using the Microsoft Kinect sensor (3.3GB). We collect eight interactions: approaching, departing, pushing, kicking, punching, exchanging objects, hugging, and shaking hands from seven participants and 21 pairs of two-actor sets. Each frame contains color image, depth map, and 3-dimensional coordinates of 15 joints from each person.
Project page
Project page

90 images from the SUN09 Dataset. Object segmentations by human subjects for all 90 images are provided as part of SUN09. Clutter rankings done by 15 human subjects are provided (21.5MB).
Project page
Project page
Codes
Higher-order Surface Matching and Registration

Topology Cuts for Image Segmentation