ANN - Approximate Nearest Neighbors
ANN is a library written in the C++ programming language to support both
exact and approximate nearest neighbor searching in spaces of various
dimensions. It was implemented by David M. Mount of the University of
Maryland, and Sunil Arya of the Hong Kong University of Science and
Technology. ANN (pronounced like the name ``Ann'') stands for Approximate
Nearest Neighbors. ANN is also a testbed containing programs and
procedures for generating data sets, collecting and analyzing statistics on
the performance of nearest neighbor algorithms and data structures, and
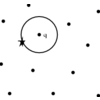
visualizing the geometric structure of these data structures.In the nearest neighbor problem a set P of data points in d-dimensional
space is given. These points are preprocessed into a data structure, so
that given any query point q, the nearest (or generally k nearest) points
of P to q can be reported efficiently. ANN is designed for data sets that
are small enough that the search structure can be stored in main memory
(in contrast to approaches from databases that assume that the data
resides in secondary storage). The distance between two points can be
defined in many ways. ANN assumes that distances are measured using any
class of distance functions called Minkowski metrics. These include the well
known Euclidean distance, Manhattan distance, and max distance.
Download Files (local site)David Mount's WebpageLibrary for Approximate Nearest Neighbor Searching
Problem Links
This page last modified on 2008-07-10
.
www.algorist.com