
Learning Models for Illumination, Shadows and Shading

Pictures result from the complex interactions between the geometry, illumination and materials present in a scene. Estimating any of these factors individually from a single image leads to severely underconstrained problems.
Having a rough geometric model of the scene has allowed us to jointly estimate the illumination and the cast shadows of the scene. We solve the joint estimation using graphical models and novel shadow cues such as the bright channel. We further develop our method so as to be able to perform inference on not only illumination and cast shadows but also on the scene's geometry, thus refining the initial rough geometrical model.
Scene understanding methods that want to account for illumination effects require reasonable shadow estimates. General shadow detection from a single image is a challenging problem, especially when dealing with consumer grade pictures (or pictures from the internet). We investigate methods for single image shadow detection based on learning the appearance of shadows from labelled data sets. Our methods are the state of the art in shadow detection.
In our work we take advantage of domain knowledge in illumination and image formation for feature design, as well as extensive use of machine learning techniques such as graphical models (MRFs, CRFs) and classifiers (SVMs).
Ongoing lines of work are: illumination based scene understanding, shadow removal and shadow segmentation.
- Selected publications:
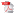 Leave-One-Out Kernel Optimization for Shadow Detection, Tomas F Yago Vicente, Minh Hoai, Dimitris Samaras, IEEE International Conference on Computer Vision (ICCV) 2015, Santiago/Chile
Leave-One-Out Kernel Optimization for Shadow Detection, Tomas F Yago Vicente, Minh Hoai, Dimitris Samaras, IEEE International Conference on Computer Vision (ICCV) 2015, Santiago/Chile
- Single Image Shadow Removal via Neighbor Based Region Relighting, Tomas F Yago Vicente, Dimitris Samaras, In Proceedings of the IEEE Color and Photometry in Computer Vision Workshop (CPCV) 2014 (in conjunction with ECCV 2014), Zürich/Switzerland
- The Photometry of Intrinsic Images, Marc Serra, Olivier Penacchio, Robert Benavente, Maria Vanrell, Dimitris Samaras, Computer Vision and Pattern Recognition (CVPR) 2014, Ohio/USA
- Simultaneous Cast Shadows, Illumination and Geometry Inference Using Hypergraphs, Alexandros Panagopoulos, Chaohui Wang, Dimitris
Samaras, Nikos Paragios, In IEEE Transactions on Pattern Analysis
and Machine Intelligence (PAMI) Febrary 2013, 35(2): 437-449
- Intrinsic Image Evaluation On Synthetic
Complex Scenes, Shida Beigpour, Marc Serra, Joost van de
Weijer, Robert Benavente, Maria Vanrell, Olivier Penacchio, Dimitris
Samaras, In Proceedings of the IEEE International Conference on
Image Processing (ICIP) 2013, Melbourne/Australia
- Single Image Shadow Detection using
Multiple Cues in a Supermodular MRF, Tomas F. Yago Vicente,
Chen-Ping Yu, Dimitris Samaras, British Machine Vision Conference
(BMVC) 2013, Bristol/England
- Reconstructing Shape from Dictionaries of Shading Primitives,
Alexandros Panagopoulos, Sunil Hadap, Dimitris Samaras, In
Proceedings of the 11th Asian Conference on Computer Vision (ACCV)
2012, Daejeon/Korea
- Robust Shadow and Illumination
Estimation Using a Mixture Model, Panagopoulos A., Samaras D.,
Paragios N., In CVPR'09, June 2009
- Tomas F. Yago Vicente
- Alexandros Panagopoulos
The Photometry of Intrinsic Images
[publications]
Intrinsic characterization of scenes is often the best way to overcome the illumination variability artifacts that com- plicate most computer vision problems, from 3D reconstruction to object or material recognition. This paper examines the deficiency of existing intrinsic image models to accurately account for the effects of illuminant color and sensor characteristics in the estimation of intrinsic images and presents a generic framework which incorporates insights from color constancy research to the intrinsic image decomposition problem. The proposed mathematical formulation includes information about the color of the illuminant and the effects of the camera sensors, both of which modify the observed color of the reflectance of the objects in the scene during the acquisition process. By modeling these effects, we get a “truly intrinsic” reflectance image, which we call absolute reflectance, which is invariant to changes of illuminant or camera sensors. This model allows us to represent a wide range of intrinsic image decompositions depending on the specific assumptions on the geometric properties of the scene configuration and the spectral properties of the light source and the acquisition system, thus unifying previous models in a single general framework. We demonstrate that even partial information about sensors improves significantly the estimated reflectance images, thus making our method applicable for a wide range of sensors. We validate our general intrinsic image framework experimentally with both synthetic data and natural images.
Publications
- The Photometry of Intrinsic Images, Marc Serra, Olivier Penacchio, Robert Benavente, Maria Vanrell, Dimitris Samaras, Computer Vision and Pattern Recognition (CVPR) 2014, Ohio/USA
[ BibTex ] - Intrinsic Image Evaluation On Synthetic
Complex Scenes, Shida Beigpour, Marc Serra, Joost van de
Weijer, Robert Benavente, Maria Vanrell, Olivier Penacchio, Dimitris
Samaras, In Proceedings of the IEEE International Conference on
Image Processing (ICIP) 2013, Melbourne/Australia
[ BibTex ]
Simultaneous Cast Shadows, Illumination and Geometry Inference Using Hypergraphs
[publications]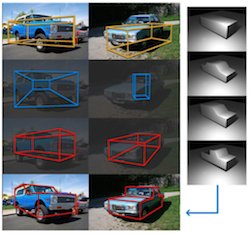
The cast shadows in an image provide important information about illumination and geometry. In this paper, we utilize this information in a novel framework in order to jointly recover the illumination environment, a set of geometry parameters, and an estimate of the cast shadows in the scene given a single image and coarse initial 3D geometry. We model the interaction of illumination and geometry in the scene and associate it with image evidence for cast shadows using a higher order Markov Random Field (MRF) illumination model, while we also introduce a method to obtain approximate image evidence for cast shadows. Capturing the interaction between light sources and geometry in the proposed graphical model necessitates higher order cliques and continuous- valued variables, which make inference challenging. Taking advantage of domain knowledge, we provide a two-stage minimization technique for the MRF energy of our model. We evaluate our method in different datasets, both synthetic and real. Our model is robust to rough knowledge of geometry and inaccurate initial shadow estimates, allowing a generic coarse 3D model to represent a whole class of objects for the task of illumination estimation, or the estimation of geometry parameters to refine our initial knowledge of scene geometry, simultaneously with illumination estimation.
Publications
- Leave-One-Out Kernel Optimization for Shadow Detection, Tomas F Yago Vicente, Minh Hoai, Dimitris Samaras, IEEE International Conference on Computer Vision (ICCV) 2015, Santiago/Chile
[ BibTex ] - Single Image Shadow Removal via Neighbor Based Region Relighting, Tomas F Yago Vicente, Dimitris Samaras, In Proceedings of the IEEE Color and Photometry in Computer Vision Workshop (CPCV) 2014 (in conjunction with ECCV 2014), Zürich/Switzerland
[ BibTex ] - Simultaneous
Cast Shadows, Illumination and Geometry Inference Using
Hypergraphs, Alexandros Panagopoulos, Chaohui Wang, Dimitris
Samaras, Nikos Paragios, In IEEE Transactions on Pattern Analysis
and Machine Intelligence (PAMI) Febrary 2013, 35(2): 437-449
[ BibTex ] - Single Image Shadow Detection using
Multiple Cues in a Supermodular MRF, Tomas F. Yago Vicente,
Chen-Ping Yu, Dimitris Samaras, British Machine Vision Conference
(BMVC) 2013, Bristol/England
[ BibTex ] - Reconstructing Shape from Dictionaries of Shading Primitives,
Alexandros Panagopoulos, Sunil Hadap, Dimitris Samaras, In
Proceedings of the 11th Asian Conference on Computer Vision (ACCV)
2012, Daejeon/Korea
[ BibTex ] - Illumination
Estimation from Shadow Borders, Panagopoulos, A.,
Yago-Vicente, T., Samaras, D., In Proceedings of the IEEE Color and
Photometry in Computer Vision Workshop (CPCV) 2011 (in conjunction
with ICCV 2011), Barcelona, Spain
[ BibTex ] - Illumination
Estimation and Cast Shadow Detection through a Higher-order
Graphical Model, Panagopoulos A., Wang C., Samaras D.,
Paragios N., In Proceedings of the IEEE International Conference on
Computer Vision and Pattern Recognition (CVPR) 2011, Colorado
Springs, CO.
[ BibTex ] - Estimating
Shadows with the Bright Channel Cue, Panagopoulos A., Wang C.,
Samaras D., Paragios N., CRICV 2010 (in conjunction with ECCV'10),
2010
[ BibTex ] - Robust Shadow and Illumination
Estimation Using a Mixture Model, Panagopoulos A., Samaras D.,
Paragios N., In CVPR'09, June 2009
Illumination Modeling for Computer Vision & Computer Graphics
We are researching problems related with the interaction of illumination and 3D shape in images for Computer Vision (shape estimation, tracking, recognition) and Computer Graphics (image relighting, augmented reality), in which object appearance is significantly influenced by the illumination conditions of the scene. Optical images are formed by measurements of the light that reflects from surfaces of various materials and orientations in 3D space. Effective approaches to numerous problems related to visual appearance, from photo-realistic image synthesis, to convincing Augmented Reality environments to object recognition, rely on the accuracy and efficiency of models of visual appearance of objects, thus motivating the study of the image formation process. In addition to knowing the geometry of the scene and of the cameras, we also need to model the reflectance properties of the surfaces being imaged and the configuration of illumination sources in the scene. In the general case it is impossible to determine simultaneously shape, reflectance and illumination without having any prior knowledge of the scene, so we have been working on a number of subproblems where different priors are used.
We have also developed novel solutions for 3D
Shape estimation from shading from single images and
href="content/papers/2000/samaras-cvpr2000.pdf">stereo sets, multiple
light source estimation,
visual tracking of
deformable objects with little texture,
and face recognition
under arbitrary illumination.
- Selected publications:
- Estimation
of Multiple Directional Light Sources for Synthesis of Augmented
Reality Images, Yang Wang and Dimitris Samaras, In Graphical
Models, July 2003 (Special Issue on Pacific Graphics 2003), Volume
65, Issue 4, pp. 185-205.
[ BibTex ] - Multiple
Directional Illuminant Estimation from a Single Image, Yang
Wang and Dimitris Samaras, In Proc. IEEE Workshop on Color and
Photometric Methods in Computer Vision (in conjunction with ICCV
2003).
- Incorporating
Illumination Constraints in Deformable Models for Shape and Light
Direction Estimation, Dimitris Samaras and Dimitris Metaxas,
In IEEE Trans. PAMI Feb. 2003, Volume 65, Issue 4, pp. 247-264.
[ BibTex ] - Variable Albedo Surface Reconstruction
from Stereo and Shape from Shading, Dimitris Samaras, Dimitris
Metaxas, Pascal Fua, Yvan G. Leclerc, In Proc. CVPR 2000, pp. I:
480-487.
[ BibTex ] - Capturing
long-range correlations with patch models, Vincent Cheung,
Nebojsa Jojic, Dimitris Samaras, in CVPR 2007, pp.1-8
- Face
Re-Lighting from a Single Image under Harsh Lighting Conditions,
Yang Wang, Zicheng Liu, Gang Hua, Zhen Wen, Zhengyou Zhang, Dimitris
Samaras, CVPR 2007, pp.1-8
- Yang Wang
In Dr. Samaras's Ph.D. thesis, he proposed a method for the incorporation of any type of illumination constraints in deformable model frameworks. If the light source direction is unknown, both light source and object shape can be recovered, in . The applicability of the above methods was extended with the integration of shape from shading (SFS) and stereo, for non-constant albedo and non-uniformly Lambertian surfaces. In the case of moving objects, optical flow becomes part of a generalized illumination constraint, which was used for visual tracking of deformable objects with little texture.
- Incorporating
Illumination Constraints in Deformable Models for Shape and Light
Direction Estimation, Dimitris Samaras and Dimitris Metaxas,
In IEEE Trans. PAMI Feb. 2003, Volume 65, Issue 4, pp. 247-264.
[ BibTex ] - Integration of Illumination Constraints in Deformable Models. PhD Thesis, University of Pennsylvania, 2001.
- Variable Albedo Surface Reconstruction
from Stereo and Shape from Shading, Dimitris Samaras, Dimitris
Metaxas, Pascal Fua, Yvan G. Leclerc, In Proc. CVPR 2000, pp. I:
480-487.
[ BibTex ] - Coupled
Lighting Direction and Shape Estimation from Single Images,
Dimitris Samaras and Dimitris Metaxas, In Proc. ICCV 1999, pp.
868-874.
[ BibTex ] - Incorporating Illumination Constraints in Deformable Models, Dimitris Samaras and Dimitris Metaxas, In Proc. CVPR 1998, pp. 322-329.
Often it is impossible to know exactly either the reflectance properties or the shape of an object, but we can have a statistical prior for them, especially nowadays that image databases are ubiquitous. This led us to study the statistical properties of shape and illumination for the case of particular object categories. When applied to faces this allows for significant improvements to face recognition technology. More details can be found in the Face Recognition section.
Multiple Directional Illuminant Estimation from a Single Image
[publications]
We present a new method for the detection and estimation of multiple directional illuminants, using only one single image of an object of arbitrary known geometry. The surface is not assumed to be pure Lambertian, instead, it can have both Lambertian and specular properties. We propose a novel methodology that integrates information from shadows, shading and specularities in the presence of strong directional sources of illumination, even when significant non-directional sources exist in the scene. Since the specular spots have much sharper intensity changes than the Lambertian part, we can locate them in the image of the sphere by first down-sampling the image and then applying a region growing algorithm. Once the specularities have been roughly segmented, the remaining regions of the image are mostly Lambertian, and can be segmented into regions, with each region illuminated by a different set of sources, in a robust way. The regions are separated by boundaries consisting of critical points (points where one illuminant is perpendicular to the normal). Our region-based recursive least-squares method is impervious to noise and missing data. The illuminant estimation can be further refined by making use of shadow information when available, in a novel, integrated single-pass estimation. The method is generalized to objects of arbitrary known geometry, by mapping their normals to a sphere. Furthermore, we introduce a hybrid approach that combines our method with spherical harmonic representations of non-directional light sources, when such sources are present in the scene. We demonstrate experimentally the accuracy of our method, both in detecting the number of light sources and in estimating their directions, by testing on synthetic and real images.
Publications
- Estimation
of Multiple Directional Light Sources for Synthesis of Augmented
Reality Images, Yang Wang and Dimitris Samaras, In Graphical
Models, July 2003 (Special Issue on Pacific Graphics 2003), Volume
65, Issue 4, pp. 185-205.
[ BibTex ] - Multiple
Directional Illuminant Estimation from a Single Image, Yang
Wang and Dimitris Samaras, In Proc. IEEE Workshop on Color and
Photometric Methods in Computer Vision (in conjunction with ICCV
2003).
- Estimation
of Multiple Directional Light Sources for Synthesis of Mixed
Reality Images, Yang Wang and Dimitris Samaras, In Proc.
Pacific Graphics 2002, pp. 38-47.
[ BibTex ] - Estimation
of Multiple Directional Light Sources for Synthesis of Mixed
Reality Images, Yang Wang and Dimitris Samaras, In Proc.
Pacific Graphics 2002, pp. 38-47.