
In the future computers will converse with users fluidly and in multiple languages. In fact, one can anticipate translator applications that will allow speakers of different languages to converse (in near real-time) with one another. (Comprehending human language is a related research field called natural language processing).
Speech recognition brings all of the richness of command line interfaces with more ease-of-use than GUI's. Speech synthesis provides output that facilitates user multitasking in "busy eyes" situations, like driving a car.
Speech interfaces are commonly added to GUI's, for example as an accessibility feature for people with vision impairment. But speech interfaces are also used in conjunction with other novel interfaces, such as gesture, in VR environments to create a natural and immersive experience.
Linguist and author Noam Chomsky using iSign, a speech recognition application.
Phonemes and Hidden Markov Models
It would be possible to record a large dictionary of words, create template spectrographs, and to scan incoming speech waveforms for a match. But basic English has at least 50,000 words.
Phonemes are the linguistic units that make up speech. English has about 40 phonemes - consonant, vowel, and other sounds - that make up the spoken language. Phonemes are extracted from the sound wave by passing the waveform through a Fourier Transform. This allows the waveform's frequency to be analyzed, and the phonemes to be compared to template phonemes for a match.
Hidden Markov Models are used in speech recognition to inform computer interpretation. A word is actually a chain of phonemes. The chains can branch and HMM evaluates the probability of various branchings and biases the computer's interpretation.
Sentences are chains of words. In continuous speech recognition (like dictation) HMM can evaluate the probability of the interpretation of a word in a sentence by looking at it in the context of other words in the sentence. Did the speaker mean "bow" (as in a boat) or "bough" (as on a tree)?
Benefits of Speech
• Data entry possible without keyboard
- as in mobile computing applications
• Excellent for busy hands situations
- as in operating a vehicle or equipment
• Bad typists, bad spelling, the awkward QWERTY keyboard
• Natural mode of interaction
• People with visual disabilities
Problems of Speech
• Controlling things, describing complex concepts, non-literal terms
• High expectations- A three-year old is better than current technology
• Speech output sounds unnatural
• Input is error prone
• Asymmetrical- speech input is faster than typing
- speech output is slower than reading• Public mode of interaction
- interactions may be overheard
• Noisy environments
Speech Synthesis
• Written text transformed into speech
- text-to-speech
• Two types of synthesiser
- parameterised
- concatenative• Parameterised
- formant based - use rules based on signal from spoken input
- articulatory - use model of vocal tract• Parameterised is more like musical instrument synthesis
• Concatenative - word
- just record all the words you need
- good for small sets• Concatenative - phoneme
- phoneme - smallest unit of speech that differentiates one word from another
- makes more natural sounding speech• Concatenative is more like sound sampling
Above, BALDI uses synthesized speech to teach deaf children how to form words.
Speech Synthesis Problems
• Understandability
• Words not in dictionary
• Prosody- stress, pitch, intonation
Speech Recognition Issues
• Continuous versus Discrete recognition
• Discrete
- improves accuracy
- reduce computation• Continuous
- hard to do
- natural / fast
Itisverysimilartotryingtoreadtextwithallofthespacesremoved• Speaker dependent versus independent
• Dependent
- requires training - takes time
- can get good recognition rates• Independent
- great for ‘walk up and use’ systems
- lower recognition rates in general• Vocabulary size
• Smaller the size the higher the recognition rates
- 10 - phone digits
- 100 - menu selection
- 10k - 60k - general dictation, email• Current desktop SR can get around 88% on large vocab
• Accuracy
• What is an error?
- out of vocabulary
- recognition failure
- mis-recognition
- insertion / deletion / substitution• Hard to tell mis-recognition
Recognition Errors
• User spoke at the wrong time
• Sentence not in grammar
• User paused too long
• Words sound alike
• Word out of vocab
• User has a cold
• Over-emphasis
Speech Interface Design
• Does the application really call for speech?
• Base the design on how people speak in the application domain
• Feedback- speech is slow
- user needs to know if speech was recognised / heard correctly
- is system processing data or waiting for input?• Latency
- time taken to recognize utterance
- pauses are confusing
Speech Prompts
• Let user know what to say next
• Explicit prompts- tell user exactly what to say
- "Welcome to the Registrar. Say 'add course', 'drop course', or 'pay tuition'."• Implicit prompts
- open ended
- more natural but allow more potential for error
- "Welcome to the Registrar. What would you like to do?"• Be brief - speech is slow
• Allow ‘barge-in’
• Can use timeouts- "Welcome to the Registrar. What would you like to do?"
<timeout>
" Say 'add course', 'drop course', or 'pay tuition'."• Could use text on screen if available
Recognition Errors
• Can be serious
- misrecognition changes the meaning of utterance
• Re-prompt with explicit choices
• Give a list of possible matches
• Allow user to spell word- problems with “e set”: b, c, d, e, g, p, t, v (z)
• Use visual cues if available
Human Issues
• Listeners will give your interface a personality and respond in human ways
• As with all dialogs, do not violate conversational conventions and politeness!
• Users may respond better to applications with a conversational avatar or agent ("talking head")
Above, animated characters sing with only the score and lyrics as input.
Speech Recognition Issues - Monosyllabic vs. Polysyllabic Words
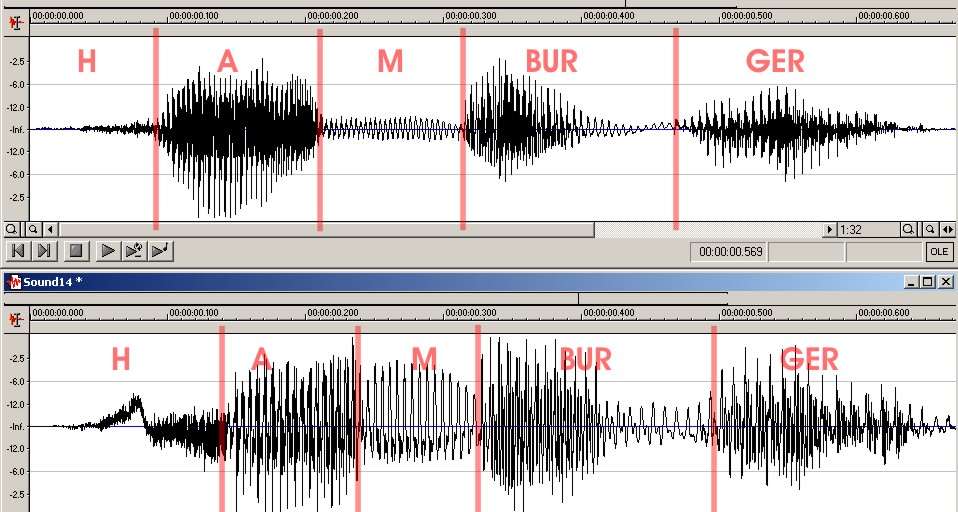
In the first testing phase for iSign we encountered some minor problems when we tried to use very short monosyllabic words. The voice recognition system had problems recognizing words like “egg”, and distinguishing between "dog" and "bug", but had no problems recognizing polysyllabic words like “hamburger”.
We tried to understand better why this was happening. We started by recording several different people saying the word “egg”. Below we can see the resulting waveforms produced by a 30 year-old Asian woman and a 32 year-old European man. We think that the differences in the waveforms are too obvious and the length of the sample is too short to give the speech recognition engine enough data to always produce correct interpretation.
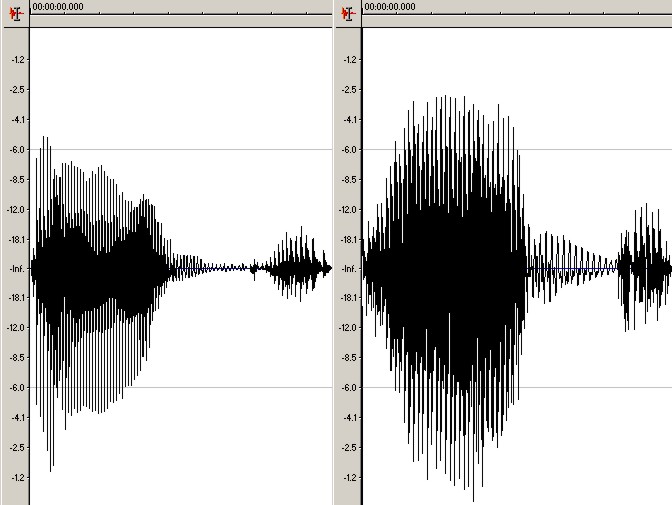
Above, waveforms for the word “egg” spoken by a woman (left)
and a man (right).
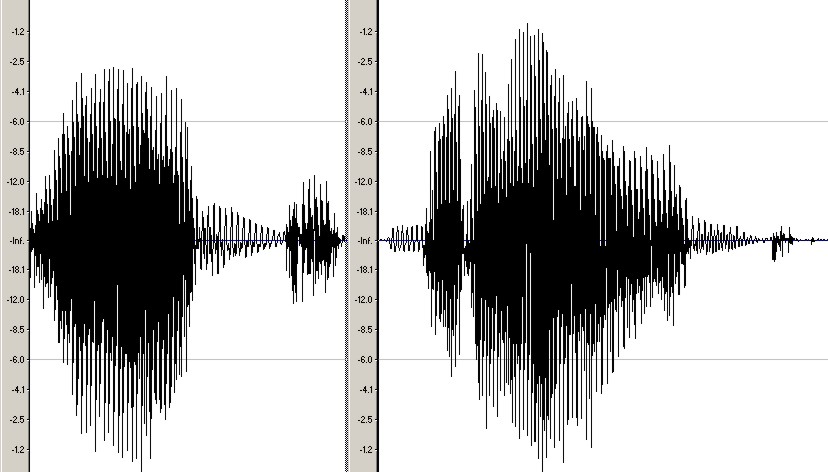
On the contrary, we see that the waveforms produced by the same two individuals while pronouncing the word “hamburger” present more similarities both in the wave structure and in the shape of the wave patterns for the same letter. We think that especially the wave structure, which differs greatly among different polysyllabic words, allows the engine to recognize words more accurately.
Above, waveforms for the word “hamburger” spoken by a woman
(top) and a man (bottom).
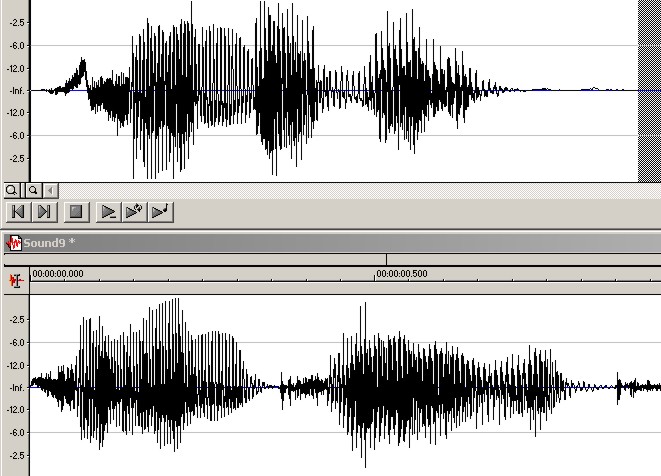
The next illustration show the strong similarities in the waveforms of two words like “egg” and “bread”. Because this similarity can confuse a voice recognition system, words to be put together in the same “album” must be selected carefully in order to have the best recognition performances. On the other hand, as shown by the very different waveforms presented in the final illustration, polysyllabic and longer words are easier to be recognized for the voice recognition system, therefore less attention must be paid when building new albums for these type of words.
Above, waveforms for the words “egg” (left) and “bread” (right), spoken by the same person.
Above, waveforms for the words “hamburger” (top) and “pancake” (bottom), spoken by the same person.
Speech on the Web
SALT:
Speech Application Language Tags (SALT) 1.0 is an extension of HTML and other markup languages (cHTML, XHTML, WML, etc.) which adds a speech and telephony interface to web applications and services, for both voice only (e.g. telephone) and multimodal browsers.
SALT is a small set of XML elements, with associated attributes and DOM (Document Object Model) object properties, events and methods, which may be used in conjunction with a source markup document to apply a speech interface to the source page. The SALT formalism and semantics are independent of the nature of the source document, so SALT can be used equally effectively within HTML and all its flavors, or with WML, or with any other SGML-derived markup.
The main top-level elements of SALT are:
< prompt …>for speech synthesis configuration and prompt playing
< listen …>for speech recognizer configuration, recognition execution and post-processing, and recording
< dtmf …>for configuration and control of DTMF collection
< smex …>for general purpose communication with platform components.
The input elements listen and dtmf also contain grammars and binding controls:
< grammar …>for specifying input grammar resources
< bind …>for processing recognition results.
listen also contains the facility to record audio input:
< record …>for recording audio input
smex also contains the binding mechanism bind to process messages.
All four top-level elements contain the
platform configuration element < param …>.
There are several advantages to using SALT with display languages such as HTML. Most notably the event and scripting models supported by visual browsers can be used by SALT applications to implement dialog flow and other forms of interaction processing without the need for extra markup, and the addition of speech capabilities to the visual page provides a simple and intuitive means of creating multimodal applications. In this way, SALT is a lightweight specification which adds a powerful speech interface to web pages, while maintaining and leveraging all the advantages of the web application.
Resources:
Speech FAQ
http://www.speech.cs.cmu.edu/comp.speech/
Speech Recognition Engines and Applications
Sample Speech Recognition Project - iSign
http://www.cs.sunysb.edu/~tony/research/iSign/iSign.html
References:
James Matthews: http://www.generation5.org
Lai & Yankelovich, CHI’99 tutorial
S. Brewster:
http://
www.dcs.gla.ac.uk/~stephen/ITHCI