
Bhavya Ghai
भव्य घई
(BHav-ye GHa-ee)
Applied Scientist
Amazon
bghai at cs dot stonybrook dot eduBio
Dr. Bhavya Ghai is an Applied Scientist at Amazon. As a part of the People eXperience and Technology Central Science Team (PXTCS), he works on algorithmic fairness and natural language processing. Previously, he was a PhD Candidate, advised by Prof. Klaus Mueller, at the Computer Science department, Stony Brook University. His research, at the intersection of Machine Learning (ML), Human-Computer Interaction (HCI) and Data Visualization, focuses on human-centered AI approach to audit and mitigate algorithmic bias at different stages of the ML pipeline. This includes building visual interactive systems, conducting empirical studies, and developing ML models to tackle social biases based on gender, race, etc. from tabular datasets, word embeddings and classification models. His work has been featured at top-tier venues like IEEE VIS, ACM CIKM, CHI, CSCW, DIS and ASSETS. He is the recipient of multiple awards including Bloomberg Immersion fellowship, Data Science for Social Good fellowship by Georgia Tech, Chairman Fellowship Award by Stony Brook University, Junior Researcher Award by the Institute of Advanced Computational Sciences, etc. During his academic life, he interned at prestigious institutions like Twitter, IBM Research, Bell Labs, Georgia Tech and IIT Delhi. He earned his bachelor’s and master’s degree in Information Technology from Indian Institute of Information Technology, Gwalior in 2016.
Research Interests:
- Algorithmic Fairness
- Human-Centered AI
- Data Visualization
- Natural Language Processing
- Explainable AI
- Human Computer Interaction
Recent Updates
- 6 Feb'23 Joined Amazon as an Applied Scientist!
- 6 Dec'22 Defended my PhD thesis!
- Aug'22 My first ever patent titled Optimizing a Machine Learning System is now online!
- Aug'22 Our paper on cascaded debiasing interventions got accepted to ACM CIKM 2022!
- July'22 Really glad that our paper on Fairness in AI got accepted to IEEE VIS 2022!
- May'22 Excited to start my summer internship with Twitter's META team!
- April'22 Our work on social biases in creative storytelling got accepted to ACM DIS 2022
- June'21 Our work on building smart writing tool for People who Stutter got accepted to ACM ASSETS 2021
- Feb'21 Our paper on Intersectional Social biases in Word Embeddings accepted to LBW, ACM SIGCHI 2021
- Aug'20 Our work on Explainable Active Learning is accepted @ACM Conference on Computer-supported Cooperative Work, CSCW 2020
- July'20 Paper accepted @ Workshop on Data Science with Human in the Loop, ACM SIGKDD Conference 2020
- Feb'20 Paper accepted @ Fair & Responsible AI Workshop, ACM SIGCHI Conference 2020, Hawaii
- Feb'20 Presented a poster on speech recognition @AAAI Conference 2020, New York
- Oct'19 Presented my PhD research @ Doctoral Colloquium, IEEE VIS Conference, Vancouver
- Oct'19 Presented upcoming research titled "Measuring social biases in human annotators using counterfactual queries in Crowdsourcing" @BHCC 2019 [Abstract | Slides]
- Aug'19 Awarded with IACS Junior Researcher Award Again! by IACS, Stony Brook University [media]
- Summer'19 Research Intern @ IBM T.J. Watson Research center, Yorktown Heights, NY
- Mar'19 Won 3rd Prize @SBU 3 Minute Thesis Competition!
- Feb'19 Won Best Research Talk Award! @GRD 2019
- Dec'18 My research on "Tackling Algorithmic Bias through Human-centered AI" selected for Doctoral Consortium @FAT* Conference 2019
- Aug'18 Awarded with IACS Junior Researcher Award! by IACS, Stony Brook University [media]
- Summer'18 Research Intern at Nokia Bell Labs, Murray Hill, NJ
- Feb'18 Awarded Full Silver Scholarship for ODSC Boston
- Oct'17 Presented my poster titled 'Visualization of Multivariate Data with Network Constraints using Multi-Objective Optimization.' at IEEE Vis 2017
- Sept'17 Presented our paper titled 'Coupling Data Science with Participatory Planning for Equity in Urban Renewal Programs: An Analysis of Atlanta's Anti-Displacement Tax Fund' at Data Science for Social Good Conference, Chicago
- Aug 26,2017 Awarded Travel Grant award for Data Science for Social Good Conference, Chicago
- July 28,2017 Awarded with Bloomberg Immersion Fellowship!
- Summer'17As DSSG Fellow, Worked with Prof. Ellen Zegura at Georgia Tech, Atlanta
- Jan'17 Teaching Assistant for CSE CSE 337 Scripting languages for Spring'17
- Sept'16 Teaching Assistant for CSE 303 Theory of Computation & CSE 214 Computer Science II for Fall'16
- Aug'16 Awarded Chairman's Fellowship Award by CS Dept., Stony Brook University!
- Aug'16 Joined PhD program at CS department, Stony Brook University
- Jun 6,2016 Started working as Software Engineer at InfoEdge India
- May'16 Graduated with Master's in Information Technology from IIIT Gwalior
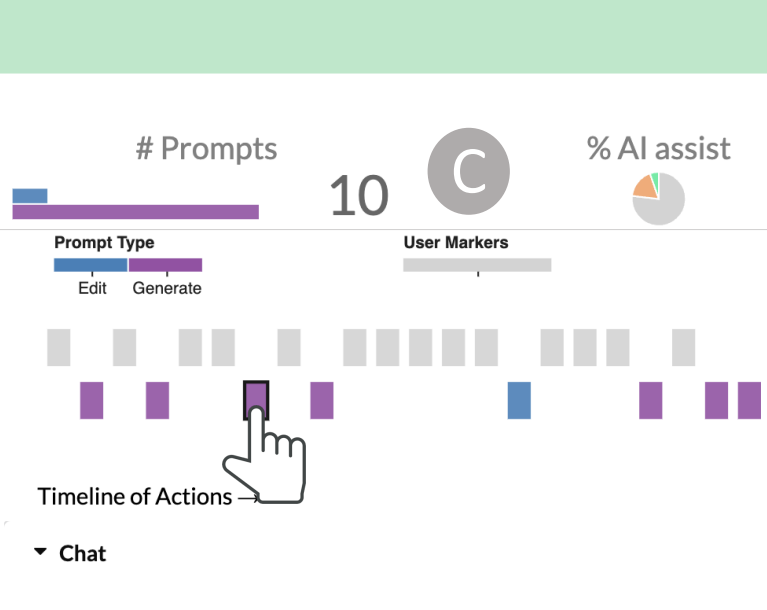
The HaLLMark Effect: Supporting Provenance and Transparent Use of Large Language Models in Writing through Interactive Visualization
Md Naimul Hoque, Tasfia Mashiat, Bhavya Ghai, Cecilia Shelton, Fanny Chevalier, Kari Kraus, Niklas Elmqvist
ACM Conference on Human Factors in Computing Systems, CHI 2024
PDF Cite
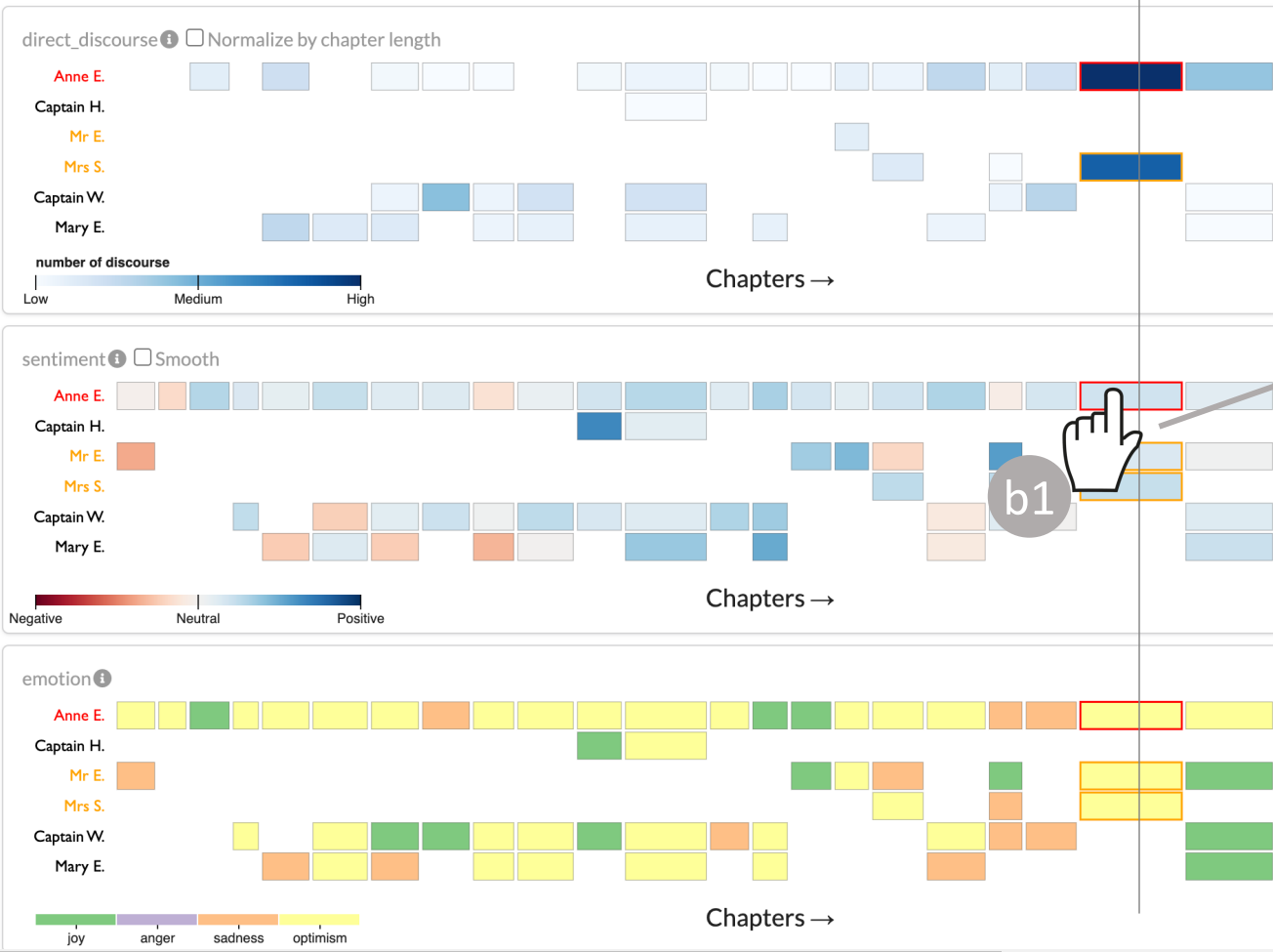
Portrayal: Leveraging NLP and Visualization for Analyzing Fictional Characters
Md Naimul Hoque, Bhavya Ghai, Kari Kraus and Niklas Elmqvist
ACM SIGCHI Conference on Designing Interactive Systems, DIS 2023
PDF Cite

Towards Fair and Explainable AI using a Human-Centered AI Approach
Bhavya Ghai
PhD Thesis, Stony Brook University
PDF Cite
D-BIAS: A Human in the Loop System for Algorithmic Bias Assessment and Mitigation
Bhavya Ghai and Klaus Mueller
IEEE Visualization Conference, Oklahoma City, VIS 2022
PDF Live Demo Demo Video Video Presentation Cite
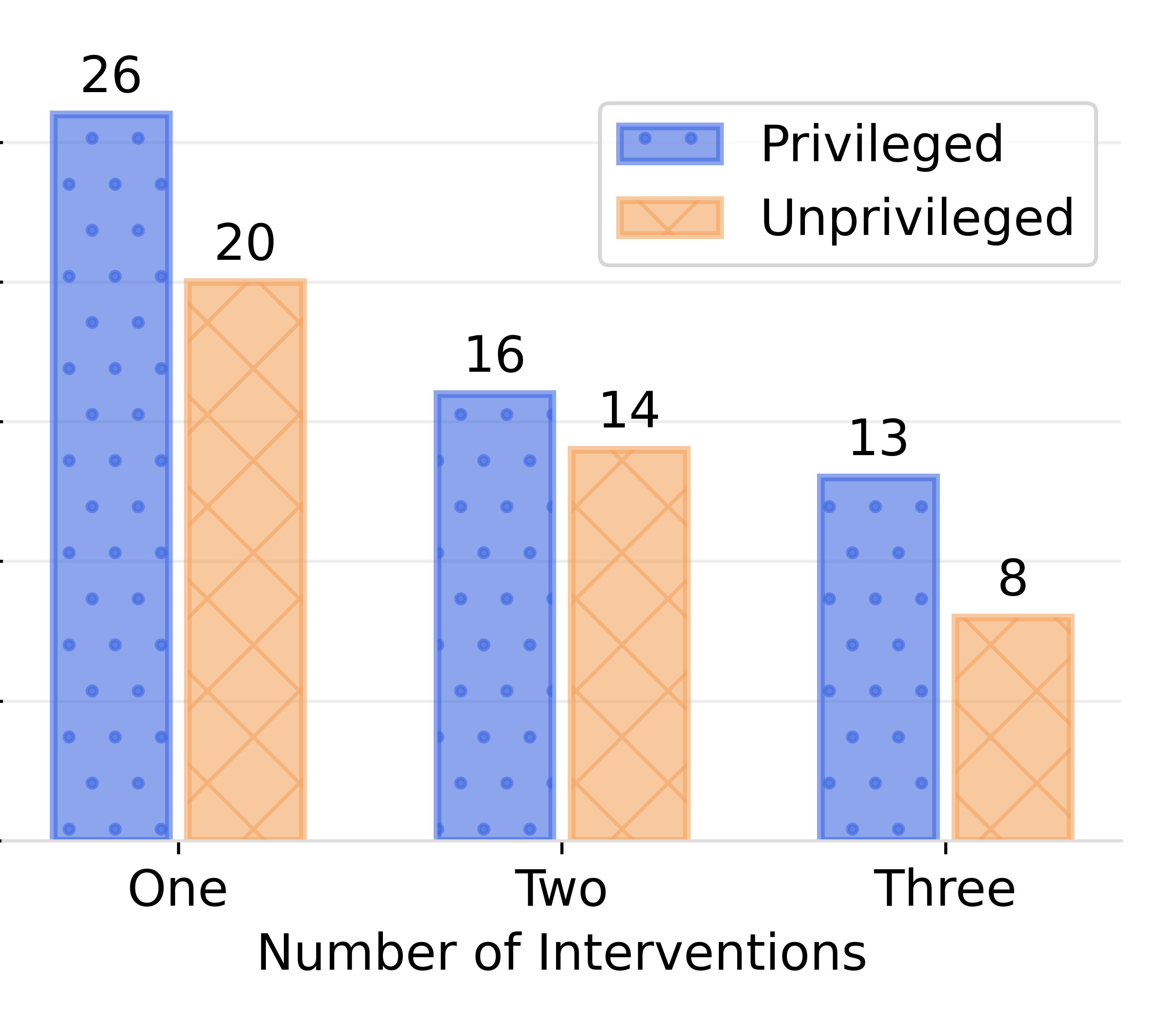
Cascaded Debiasing: Studying the Cumulative Effect of Multiple Fairness-Enhancing Interventions
Bhavya Ghai, Mihir Mishra and Klaus Mueller
ACM Conference on Information and Knowledge Management, Atlanta, CIKM 2022
PDF Code Video Cite

DramatVis Personae: Visual Text Analytics for Identifying Social Biases in Creative Writing
Md Naimul Hoque, Bhavya Ghai and Niklas Elmqvist
ACM SIGCHI Conference on Designing Interactive Systems, DIS 2022
PDF Live Demo Code Cite
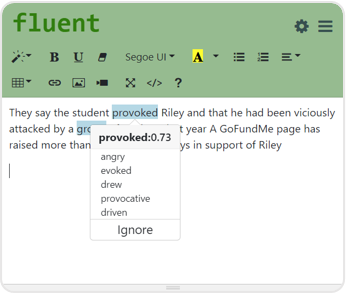
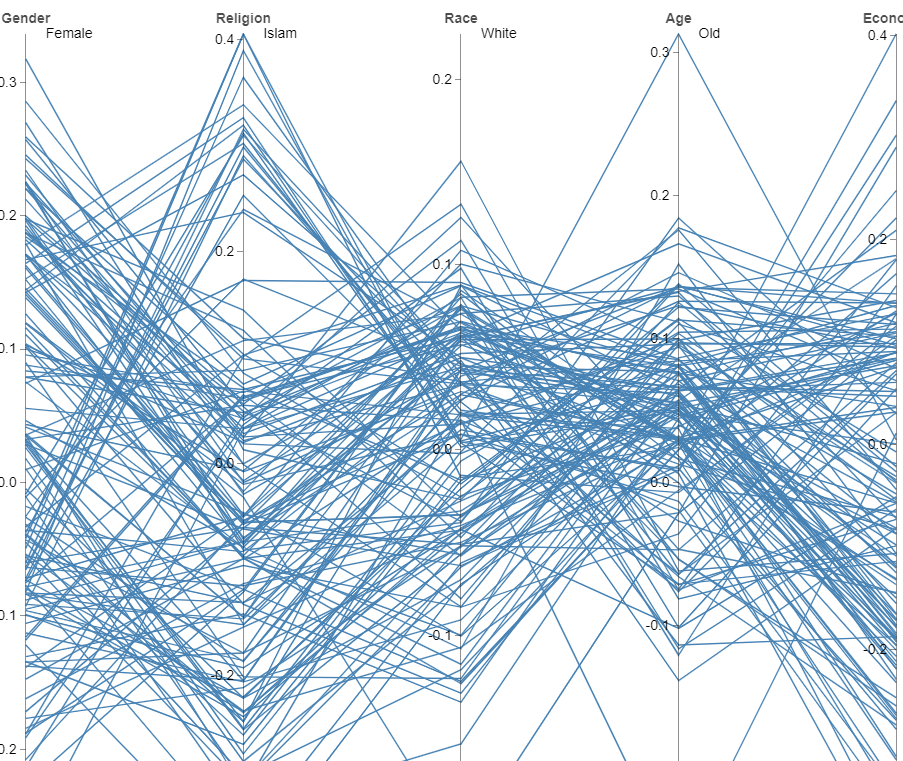
Explainable Active Learning (XAL): Toward AI Explanations as Interfaces for Machine Teachers
Bhavya Ghai, Q. Vera Liao, Yunfeng Zhang, Rachel Bellamy, Klaus Mueller
ACM Conference on Computer-Supported Cooperative Work and Social Computing, CSCW 2020
PDF Video Cite
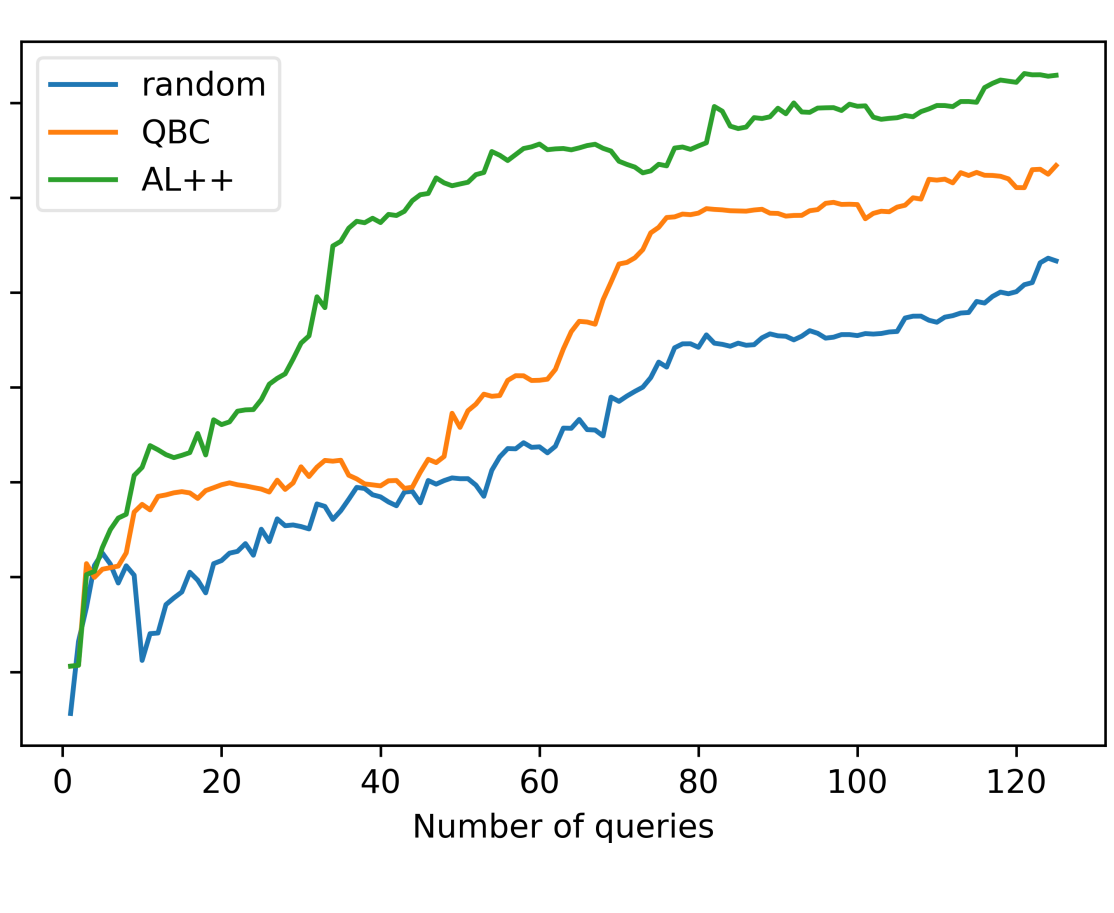
Active Learning++: Incorporating Annotator's Rationale using Local Model Explanation
Bhavya Ghai, Q. Vera Liao, Yunfeng Zhang, Klaus Mueller
Data Science with Human in the Loop Workshop
ACM Conference on Conference on Knowledge Discovery and Data Mining, KDD 2020
PDF Cite
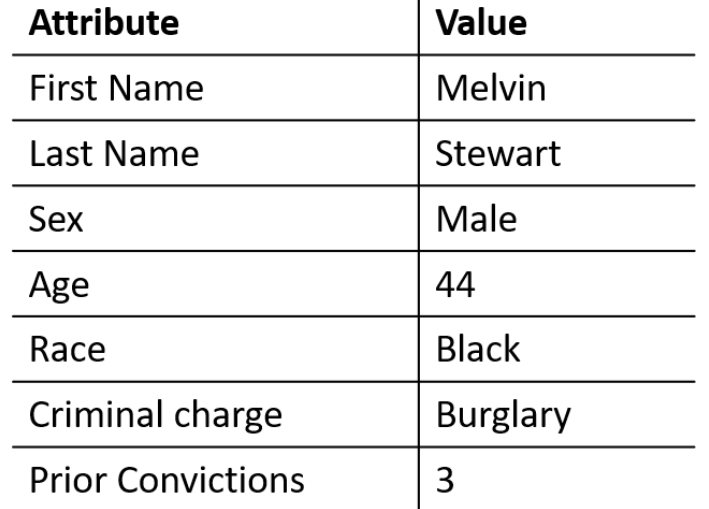
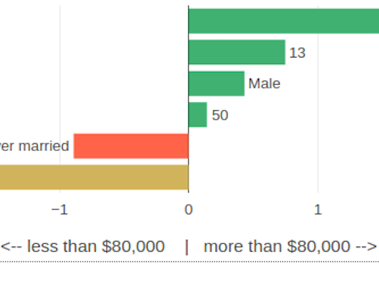
Bhavya Ghai, Q. Vera Liao, Yunfeng Zhang, Klaus Mueller
Fair & Responsible AI Workshop
ACM Conference on Human Factors in Computing Systems, Hawaii, CHI 2020
PDF Cite
Bhavya Ghai, Buvana Ramanan, Klaus Mueller
AAAI Conference on Artificial Intelligence (extended abstract), New York, NY, AAAI 2020
PDF Poster Cite
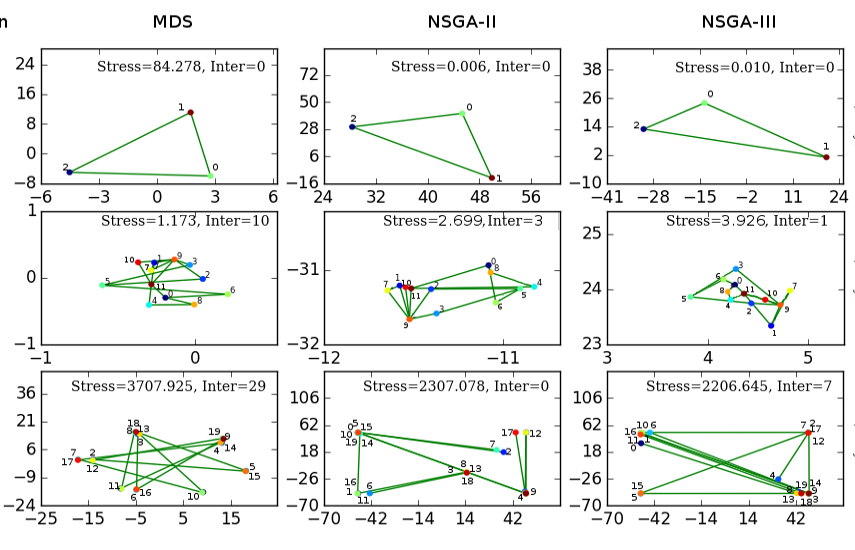
Visualization of Multivariate Data with Network Constraints using Multi-Objective Optimization.
Bhavya Ghai, Alok Mishra, Klaus Mueller
IEEE Visualization Conference (extended abstract), Phoenix, AZ, VIS 2017
PDF Poster Video
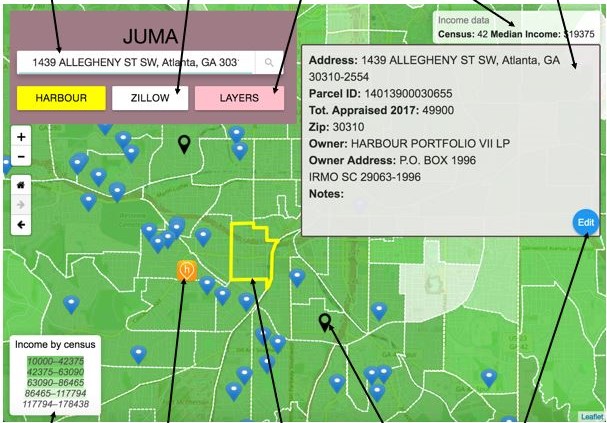
Jeremy Auerbach, Hayley Barton, Takeria Blunt, Vishwamitra Chaganti, Bhavya Ghai, Amanda Meng, Christopher Blackburn, Ellen Zegura
Bloomberg Data for Good Exchange, New York, NY, D4GX 2017
PDF Poster Cite
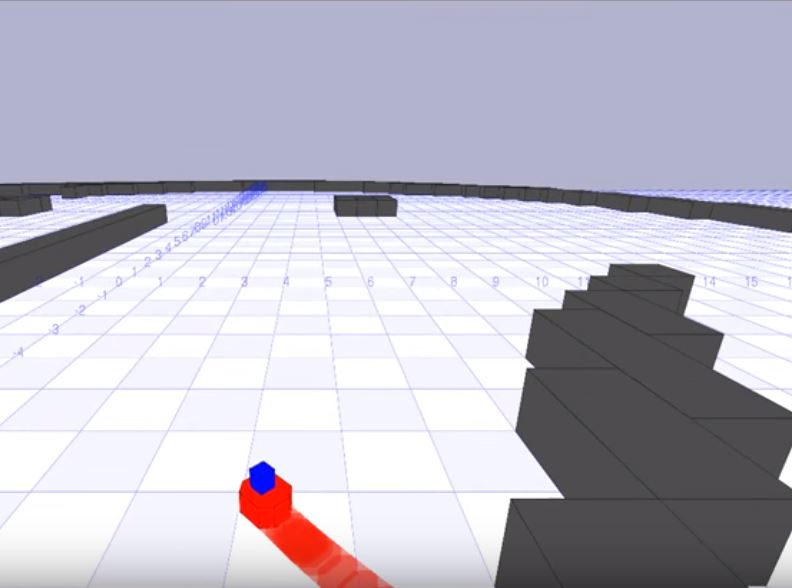
Wave Front Method Based Path Planning Algorithm for Mobile Robots.
Bhavya Ghai, Anupam Shukla
International Conference on ICT for Intelligent Systems, Ahmedabad, ICTIS 2016
PDF Cite
Energy Efficient Dynamic Nearest Node Election for Localizations of Mobile Node in Wireless Sensor Networks.
Bhavya Ghai, Girish Pradeep Bindalkar, Sanjeev Sharma, Anupam Shukla
IEEE Conference on Computational Intelligence & Computing Research, ICCIC 2015
PDF Cite
Education
| Doctor of Philosophy (Ph.D.) Master of Science (M.S.) Computer Science Department, Stony Brook University PhD Adviser: Prof. Klaus Mueller PhD Thesis: Tackling Algorithmic Bias through Human Centered AI |
2016-2022 |
| B.Tech + M.Tech (Integrated 5-year program) Indian Institute of Information Technology, Gwalior Adviser: Prof. Anupam Shukla Master's Thesis: Multi-level Ensemble Learning based Recommender System |
2011-16 |
Experience
| Applied Scientist Amazon Mentor: Dr. Srinivasan Sengamedu |
Feb'23-Present New York, NY |
| Engineering Intern Twitter (META team) Mentor: Dr. Yunfeng Zhang |
May'22-Aug'22 Remote |
| Research Intern IBM T. J. Watson Research Center Mentor: Dr. Q. Vera Liao |
Summer'19 Yorktown Heights, NY |
| Research Intern Nokia Bell Labs Mentor: Buvana Ramanan |
Summer'18 Murray Hill, NJ |
| Data Science for Social Good Fellow Georgia Institute of Technology Mentor: Prof. Ellen W. Zegura |
Summer'17 Atlanta, GA |
| Teaching Assistant Stony Brook University CSE 564 Data Visualization, CSE 214 Data Structures, CSE 337 Scripting Languages, CSE 303 Theory of Computation |
Aug'16-May'17 Stony Brook, NY |
| Research Intern Indian Institute of Technology, Delhi Adviser: Prof. G. N. Tiwari |
Summer'15 Delhi, India |
Awards & Fellowships
| Young Writer’s Award Institute of Advanced Computational Sciences, Stony Brook University | 2020 |
| Best Research Talk Award Graduate Research Day, Stony Brook | 2019 |
| Winner, 3 Minute Thesis Competition Stony Brook University | 2019 |
| Junior Researcher Award Institute of Advanced Computational Sciences, Stony Brook University | 2018, 2019 |
| Data Science for Social Good Fellowship (Declined) University of Washington | 2018 |
| Bloomberg Immersion Fellow Bloomberg | 2017 |
| Data Science for Social Good Fellow Georgia Institute of Technology, Atlanta | 2017 |
| Chairman’s Fellowship Award CS Department, Stony Brook University | 2016 |
| Post Graduate Scholarship All India Council for Technical Education | 2015, 2016 |
Technical Skills
- Programming: Python, Javascript, C++, Java, SQL, R
- Data Analytics: Jupyter Notebook, PyTorch, Keras, Spark
- Visualization: D3.js, Plotly.js, Google Charts, Leaflet, Matplotlib
Miscellaneous
- Oracle Certified Java Professional, Java SE6, 2014 [PDF]
- Served as Volunteer for ACM FAccT 2021, ACM IUI 2021, NeurIPS 2020, ACM CSCW 2020, IEEE VIS 2020, PyCon 2018, DSSG Chicago 2017
- Panel Speaker, Bloomberg Data for Good Exchange, 2017
- Travel Grant Award, Data Science for Social Good Conference, Chicago, 2017
- Full Silver Scholarship, ODSC Boston, 2018
- Travel Grant Award, PyCon, Cleveland, 2018
- Conference Scholarship, Fairness, Accountability & Transparency conference, New York, 2017
- Reviewer - IEEE PacificVis 2021, ACM SIGCHI 2022, ACM DIS 2022, IEEE VIS 2022
- Open Source Contributor - IBM AIF360





