Computer vision is the branch of artificial intelligence that focuses on providing computers with the functions typical of human vision. It is one of the most computationally intensive areas in computer science because of all the data that just one image contains, let alone a sequence of frames. In an image that is 640 pixels wide by 480 pixels high, we have over 300,000 values. Multiplied by three for Red, Green, and Blue values, we have an image that is over 900K. This can be multiplied again by 30, the frame rate for video (per second). This is over 27 million values per second to calculate.
Vision systems have to begin by reducing the amount of information. By reducing the frame size (to 240 X 180) and the number of colors (to grayscale), the amount of data can be reduced from 27 MB/sec to about 1 MB/sec. The smaller data size speeds up acquisition of data.
To speed up processing of the data, the image information is further reduced by edge detection. The changes between pixels values are computed by a filter matrix. The most common is the Laplacian matrix. Corresponding values in the matrices of the pixels being compared are multiplied, and then the values are added together to get an absolute value. Any resulting values that are above the threshold are said to denote an edge.
The edge detection filter in Photoshop applied to a grayscale image. Note the prominence of features like the eyes and lips.
Computer Vision Applications:
Industrial and home automation
- guidance for robots to correctly pick up and place manufactured parts
- quality and integrity inspection
Robotics
- guidance and telepresence
Biomedicine
- MRI and X-Ray analysis
Satellite observation of the Earth
- weather data, storm prediction
Security and Law Enforcement
- face recognition and biometric data
Performance Art and Entertainment
- gesture recognition and motion tracking
Education
Desktop Computer Vision
Computer vision is a computationally intensive field - its algorithms require a minimum of hundreds of MIPS (millions of instructions per second) to be executed in acceptable real time. The I/O of high-resolution images at video rate was traditionally a bottleneck for common computing platforms such as personal computers and workstations. To solve these problems, the research community initially turned to massive parallel-processing computer vision systems.
Dedicated computers were expensive, cumbersome, and difficult to program. In recent years, however, increased performance at the system level—faster microprocessors, faster and larger memories, and faster and wider buses—has made computer vision affordable on a wide scale. Highspeed serial buses such as the IEEE 1394 and USB 2.0 are capable of transferring hundreds of megabits per second. Moreover, video cameras have gone almost completely to digital. Consumer camcorders are based on standards such as the Digital Video (DV), which provides videos with 720 X 480 pixels/frame at a rate of 30 FPS.
Human-computer interfaces
The basic idea behind the use of computer vision in HCIs is that in several applications, computers can be instructed more naturally by human gestures than by the use of a keyboard or mouse.
Assistive Devices
In one interesting application, computer scientist James L. Crowley of the National Polytechnical Institute of Grenoble in France and his colleagues used human eye movements to scroll a computer screen up and down. A camera located on top of the screen tracked the eye movements. The French researchers reported that a trained operator could complete a given task 32% faster by using his eyes rather than a keyboard or mouse to direct screen scrolling. In general, using cameras to sense human gestures is much easier than making users wear cumbersome peripherals such as digital gloves.
 |
At left, an eye tracking system developed at SUNY Stony Brook's Visualization Lab. It is based on electro-oculography (EOG) rather than expensive reflectance based methods. The system is applicable for many virtual reality systems, video games, and for the handicapped. |
Another application that is an assistive device for visually impaired users is being developed at UMass in Amherst. VIDI, or Visual Information and Dissemination for the Visually Impaired, attempts to extract and recognize signage information, such as street signs or businesses. The application is like OCR (Optical Character Recognition) in real time in the real world. Below, an example of extraction of sign information from the landscape.

Another assistive application is The vOICe, developed at Philips Research Laboratories (Eindhoven, The Netherlands) by Peter B. L. Meijer and available online for testing. The vOICe provides a simple yet effective means of augmented perception for people with partially impaired vision. In the virtual demonstration, the camera accompanies you in your wanderings. The camera periodically scans the scene in front of you and turns images into sounds, using different pitches and lengths to encode objects’ position and size.
http://www.seeingwithsound.com/
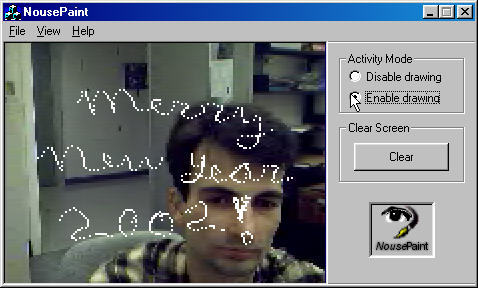
Another interesting example of an HCI application, called Nouse, for nose as a mouse, tracks the movements of your nose, and was developed by Dmitry Gorodnichy. You can play NosePong, a nose-driven version of the Pong video game, or test your ability to paint with your nose or to write with your nose. But in industry, for example, an operator might quickly stop a conveyor belt with a specific gesture detected by a camera without needing to physically push a button, pull a lever, or carry a remote control.
 |
|
Performance Art
Another application of computer vision is in performance art. In David Rockeby's "Very Nervous System" the computer watches the performer's gestures and plays synthesized music in sync with the "dance". Rockeby has packaged his gesture recognition system as an extension to the MAX programming environment, and it is called SoftVNS. Below, the gesture and what the computer "sees", and a video demonstration of the system.
http://www.davidrokeby.com/vns.html
 |
Text Rain (created by Camille Utterback & Romy Achituv) is a playful interactive installation that blurs the boundary between the familiar and the magical. Participants use the familiar instrument of their bodies, to do what seems magical - to lift and play with falling letters. Participants view a mirrored projection of themselves in black and white, combined with falling, colored text. Like rain or snow, the text lands on participants' heads and arms. The text responds to the participants' motions and can be caught, lifted, and then let fall again. If a participant accumulates enough letters along their outstretched arms, or along the silhouette of any dark object, they can sometimes catch an entire word, or even a phrase. The falling letters are not random, but are lines of a poem about bodies and language. As letters from one line of the poem fall towards the ground they begin to fade, and differently colored letters from the next line replace them from above.
http://www.creativenerve.com/textrain.html
Media interpretation
One of the more promising applications of computer vision is in the realm of image processing - a visual search engine. Instead of trying to describe in keywords what type of image you are looking for, a user can select a sample image - or attributes of it, such as color - to narrow the search of an image database. Visual Search allows people to simply ask a computer, "Have you seen anything that resembles this?" regardless of the type of information they are seeking -- whether it's photographs, illustrations, a video clip, a face, or many other types of visual digital data (including spectrograms of audio information). Visual Search can be useful for many different applications including photo and video cataloging & asset management, e-commerce comparison shopping & auctions, trademark policing, medical X-Ray & MRI diagnosis, pornography filtering, face recognition, and more.
One company that provides on-line demos of their search engine as well as an SDK developers can download is EVision.
http://www.evisionglobal.com/tech/demo.html
Facial Recognition
Images containing faces can be automatically distinguished from other images, as the results of the Face Detection Project led by Henry Schneiderman and Takeo Kanade at Carnegie Mellon University (CMU) prove. The CMU face detector is considered the most accurate for frontal face detection and is also reliable for facial profiles and three-quarter images. Anyone can submit an image which will process the image overnight and depict all detected faces with a box around them.

A related area of research is Facial Expression Analysis. Facial expression is among the most powerful, natural, and immediate means for people to communicate their emotions and intentions. The face can express emotion sooner than people verbalize or even realize their feelings. Human-observer based methods for measuring facial expression are labor intensive, qualitative, and difficult to standardize. CMU has developed a Facial Action Coding System (FACS) to automate the recognition of facial expressions, with applications in speech recognition (augmenting speech by lip reading in noisy environments), treatment of facial nerve disorders, even lie detection.
 |
|
Video surveillance
Today computer vision enables the integration of views from many cameras into a single, consistent “superimage.” Such an image automatically detects scenes with people and/or vehicles or other targets of interest, classifies them in categories such as people, cars, bicycles, or buses, extracts their trajectories, recognizes limb and arm positions, and provides some form of behavior analysis.
The analysis relies on a list of previously specified behaviors or on statistical observations such as frequent-versus-infrequent behaviors. The basic goal is not to completely replace security personnel but to assist them in supervising wider areas and focusing their attention on events of interest. Although the critical issue of privacy must be addressed before society widely adopts these video surveillance systems, the recent need for increased security has made them more likely to win general acceptance. In addition, several technical countermeasures can be taken to prevent privacy abuses, such as protecting access to video footage by way of passwords and encryption.
The University of Technology in Sydney, Australia, has developed and tested a system that can detect suspicious pedestrian behavior in parking lots. The approach is based on the assumption that a suspicious behavior corresponds to an individual’s erratic walking trajectory. The rationale behind this assumption is that a potential offender will wander about and stop between different cars to inspect their contents, whereas normal users will maintain a more direct path of travel.
The first step consists of detecting all the moving objects in the scene by subtracting an estimated “background image”—one that represents only the static objects in the scene—from the current frame. The next step is to distinguish people from moving vehicles on the basis of a form factor, such as the height:width ratio, and to locate their heads as the top region in their silhouette. In this way, the head’s speed at each frame is automatically determined. Then, a series of speed samples are repeatedly measured for each person in the scene. Each series covers an interval of about 10 s, which is enough to detect suspicious behavior patterns. Finally, a neural network classifier, trained to recognize the suspicious behaviors, provides the behavior classification.
Robot Vision
CMUcam is a low-cost, low-power sensor for mobile robots. You can use CMUcam to do many different kinds of on-board, real-time vision processing. Because CMUcam uses a serial port, it can be directly interfaced to other low-power processors such as PIC chips. At 17 frames per second, CMUcam can do the following:

Using CMUcam, it is easy to make a robot head that swivels around to track an object. You can also build a wheeled robot that chases a ball around, or even chases you around.
Resources:
UMass Computer Vision Laboratory
http://vis-www.cs.umass.edu/projects.html
Stony Brook Computer Science Visualization Lab
http://labs.cs.sunysb.edu/labs/vislab/
References:
James Matthews: http://www.generation5.org
Massimo Piccardi and Tony Jan: http://www.aip.org/tip/INPHFA/vol-9/iss-1/p18.html