Visual
Analytics and Imaging Laboratory (VAI Lab) Computer Science Department, Stony Brook University, NY |
Visual
Analytics and Imaging Laboratory (VAI Lab) Computer Science Department, Stony Brook University, NY |
Abstract: Creating compelling captions for data visualizations has been a longstanding challenge. Visualization researchers are typically untrained in journalistic reporting and hence the captions that are placed below data visualizations tend to be not overly engaging and rather just stick to basic observations about the data. In this work we explore the opportunities offered by the newly emerging crop of large language models (LLM) which use sophisticated deep learning technology to produce human-like prose. We ask, can these powerful software devices be purposed to produce engaging captions for generic data visualizations like a scatterplot. It turns out that the key challenge lies in designing the most effective prompt for the LLM, a task called prompt engineering. We report on first experiments using the popular LLM GPT-3 and deliver some promising results.
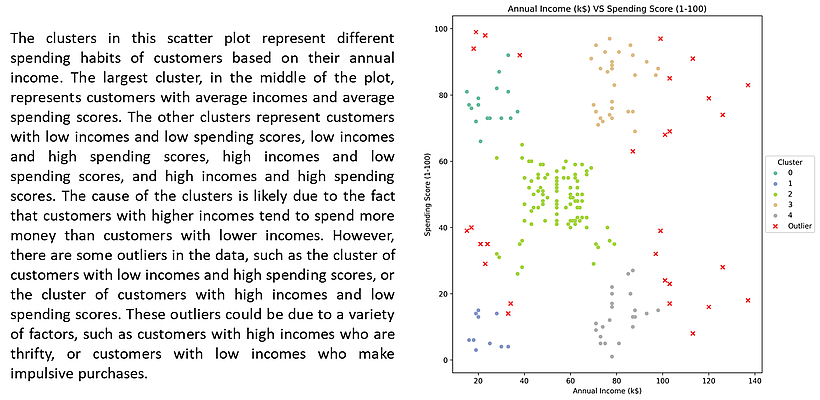
Teaser: The below shows a caption automatically produced for the scatterplot on the right:
Video: Watch this 12-minute live video captured from the presentation at the workshop:
Paper: A.Liew, K. Mueller, "Using Large Language Models to Generate Engaging Captions for Data Visualizations," NLVIZ: Exploring Research Opportunities for Natural Language, Text, and Data Visualization (NLVIZ, Workshop jointly held with IEEE VIS), Oklahoma City, OK, October, 2022 PDF | PPT