Discriminative Sub-categorization
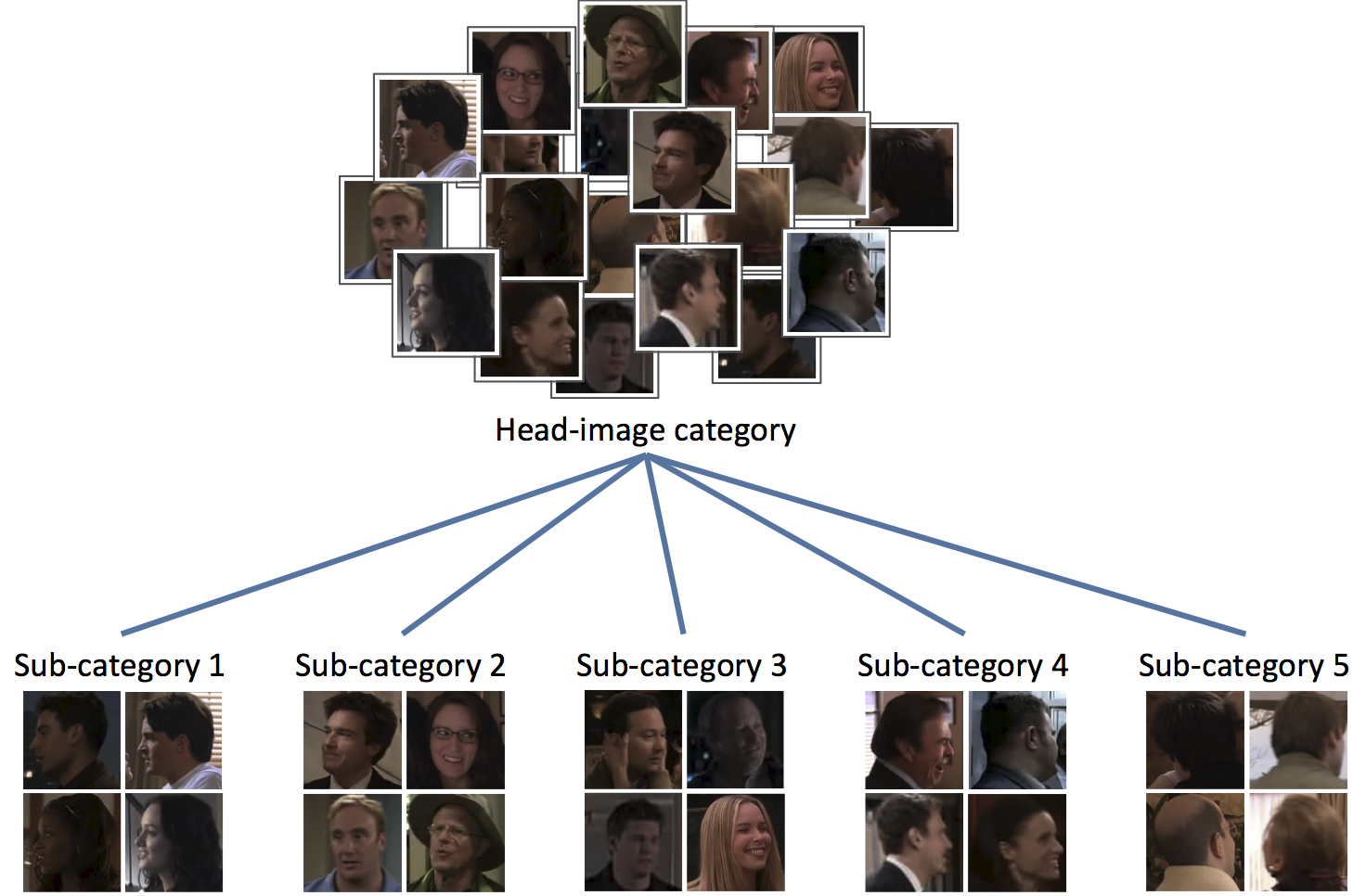 |
Figure 1. We propose a method that automatically divide a category into sub-categories.
Abstract
The objective of this work is to learn sub-categories. Rather than casting this as a problem of unsupervised clustering, we investigate a weakly supervised approach using both positive and negative samples of the category.
We make the following contributions: (i) we introduce a new model for discriminative sub-categorization which determines cluster membership for positive samples whilst simultaneously learning a max-margin classifier to separate each cluster from the negative samples; (ii) we show that this model does not suffer from the degenerate cluster problem that afflicts several competing methods (e.g., Latent SVM and Max-Margin Clustering); (iii) we show that the method is able to discover interpretable sub-categories in various datasets.
The model is evaluated experimentally over various datasets, and its performance advantages over k-means and Latent SVM are demonstrated. We also stress test the model and show its resilience in discovering sub-categories as the parameters are varied.
Overview
We introduce a new model for determining sub-categories which also utilizes negative data, i.e., examples that do not belong to the category under consideration, as a means of defining similarity and dissimilarity. In essence, a sub-category is required to contains similar items and also be well separated from the negative examples. Given a set of positive and negative examples of a category, the model simultaneously determines the cluster label of each positive example, whilst learning an SVM for each cluster, discriminating it from the negative examples, as shown in Fig. 2d.
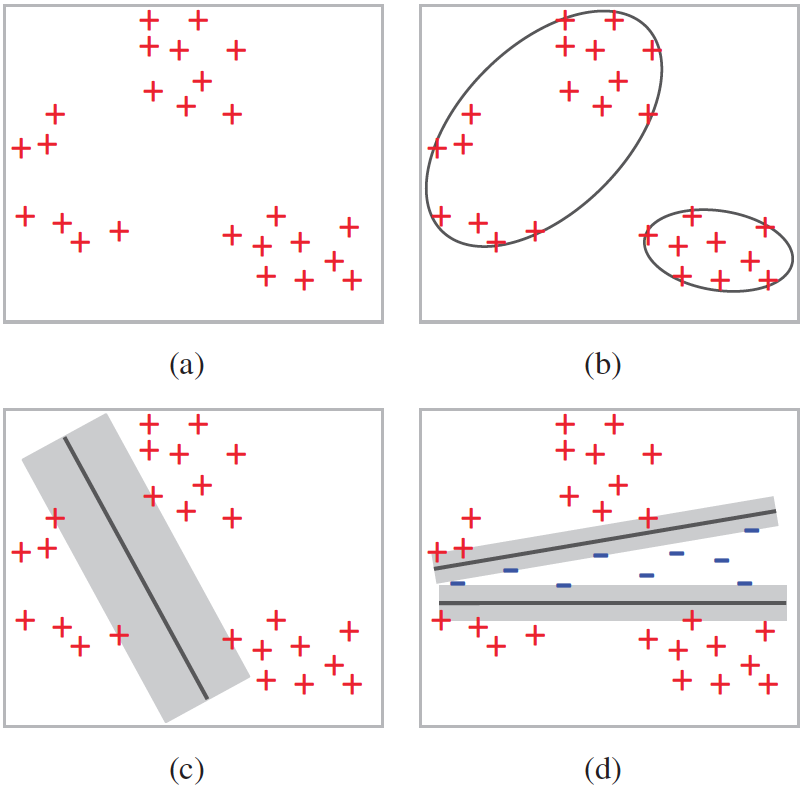 |
Figure 2. Different clustering criteria for sub-category discovery. (a): positive training examples. (b): some methods such as k-means minimizes intra-cluster distances. (c) some methods maximize separation among clusters. (d): our method maximizes the separation between clusters and negative data; it partitions positive examples (red plus) into clusters so that each cluster can be well separated from the negative examples (blue minus). |
Our model bears some similarities to Multiple-Instance SVMs, Latent SVMs, Latent Structural SVMs, and to mixtures of linear SVMs. Such methods improve classification performance using sub-categories, whereas our method emphasizes on obtaining the sub-categories. Please read the paper for details.
Results
 |
Figure 3. Five sub-categories discovered by our method. The positive components of the weight vectors that were learned by our method. Each subfigure shows 8x8 HOG cells, and each cell has 9 orientations. Dark values represent low weights and bright values represent high weights; a high weight for a particular direction at a particular cell means the model prefers to have a strong image edge of that direction at that cell. The learned weights somewhat correspond to the edge structures of the heads at different orientations. |
 |
Figure 4. High-rank images – images with highest confidence scores. High-rank images correspond to five discrete head orientations. |
 |
Figure 5. Low-rank images – images with lowest confidence scores. Low-rank images are due to: i) the regression procedure fails to localize the head region; ii) subject exhibits a rare head pose; iii) the head is occluded; or iv) the image patch has low resolution, low contrast, or motion blur. |
People
Minh Hoai Nguyen and Andrew Zisserman
Publications
Discriminative Sub-categorization.
Hoai, M. & Zisserman, A. (2013) Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Paper BibTex.
Code
Matlab/C code can be downloaded from VGG software page
Copyright notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright. These works may not be reposted without the explicit permission of the copyright holder.
Disclaimer
This software is provided for research purposes only. Usage for sale or commercial purposes is strictly prohibited. If you want to license the software, please contact the authors. This is experimental software, and no warranty is implied by this distribution. Please report bugs to the authors.