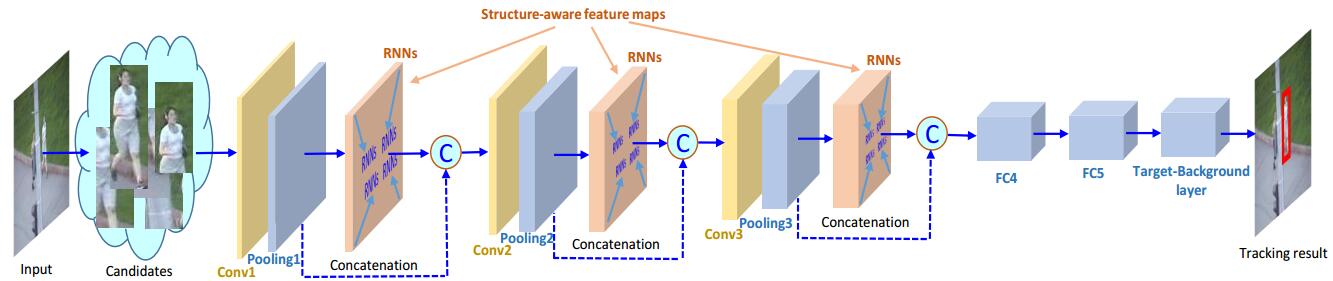
Figure 1. The proposed tracking method. The RNNs layers are used to model the structure of object.
Heng Fan and Haibin Ling
1Department of Computer and Information Sciences, Temple University, Philadelphia, USA
2HiScene Information Technologies, Shanghai, China
Convolutional neural network (CNN) has drawn increasing interest in visual tracking owing to its powerfulness in feature extraction. Most existing CNN-based trackers treat tracking as a classification problem. However, these trackers are sensitive to similar distractors because their CNN models mainly focus on inter-class classification. To deal with this problem, we use self-structure information of object to distinguish it from distractors. Specifically, we utilize recurrent neural network (RNN) to model object structure, and incorporate it into CNN to improve its robustness in presence of similar distractors. Considering that convolutional layers in different levels characterize the object from different perspectives, we use multiple RNNs to model object structure in different levels respectively. Extensive experimental results on three large-scale benchmarks, OTB100, TC-128 and VOT2015, show that the proposed algorithm outperforms other state-of-the-art methods. Figure 1 illustrates the proposed method, and Figure 2 demonstrates the structure of RNNs.
Figure 1. The proposed tracking method. The RNNs layers are used to model the structure of object.

Figure 2. Decomposition of undirected cyclic graph into four directed acyclic graphs. Images (a) and (b) are inputs. Self-structure of object is encoded in an undirected cyclic graph in images (c) and (d). Images (e), (f), (g) and (h) are four directed acyclic graphs along southeast, southwest, northwest and northeast directions.
Heng Fan and Haibin Ling. SANet: Structure-Aware Network for Visual Tracking. CVPR Workshop on DeepVision: Temporal Deep Learning, 2017. [Paper][Code][Tracking Result]
If you have any questions, please contact Heng Fan at hengfan AT temple.edu.