Abstract
We present a method that utilizes multiple camera views for the gaze target estimation (GTE) task. The approach integrates information from different camera views to improve accuracy and expand applicability, addressing limitations in existing single-view methods that face challenges such as face occlusion, target ambiguity, and out-of-view targets. Our method processes a pair of camera views as input, incorporating a Head Information Aggregation (HIA) module for leveraging head information from both views for more accurate gaze estimation, an Uncertainty-based Gaze Selection (UGS) for identifying the most reliable gaze output, and an Epipolar-based Scene Attention (ESA) module for cross-view background information sharing. This approach significantly outperforms single-view baselines, especially when the second camera provides a clear view of the person's face. Additionally, our method can estimate the gaze target in the first view using the image of the person in the second view only, a capability not possessed by single-view GTE methods. The paper also introduces a multi-view dataset for developing and evaluating multi-view GTE.
Dataset
We introduce the MVGT dataset, which contains 13,686 images collected from 28 subjects in 4 scenes using 6 calibrated cameras. We provide precise gaze annotations with a non-intrusive data collection protocol using laser pointer. Please register to download the dataset.

Example images and annotations in the MVGT dataset.
Multi-view GTE
Our model processes a pair of images as its basic operation, with the potential to analyze more images by aggregating results from multiple pairs. To leverage multi-view information, we introduce the Head Information Aggregation (HIA) module, which enhances the head embedding by incorporating facial appearance from the additional view and the geometric relationship between both views; An Uncertainty-based Gaze Selection (UGS) for identifying the gaze output from the more reliable view; An Epipolar-based Scene Attention (ESA) module for aggregating background information from the second view using epipolar geometry.
Overall framework of our multi-view GTE method.
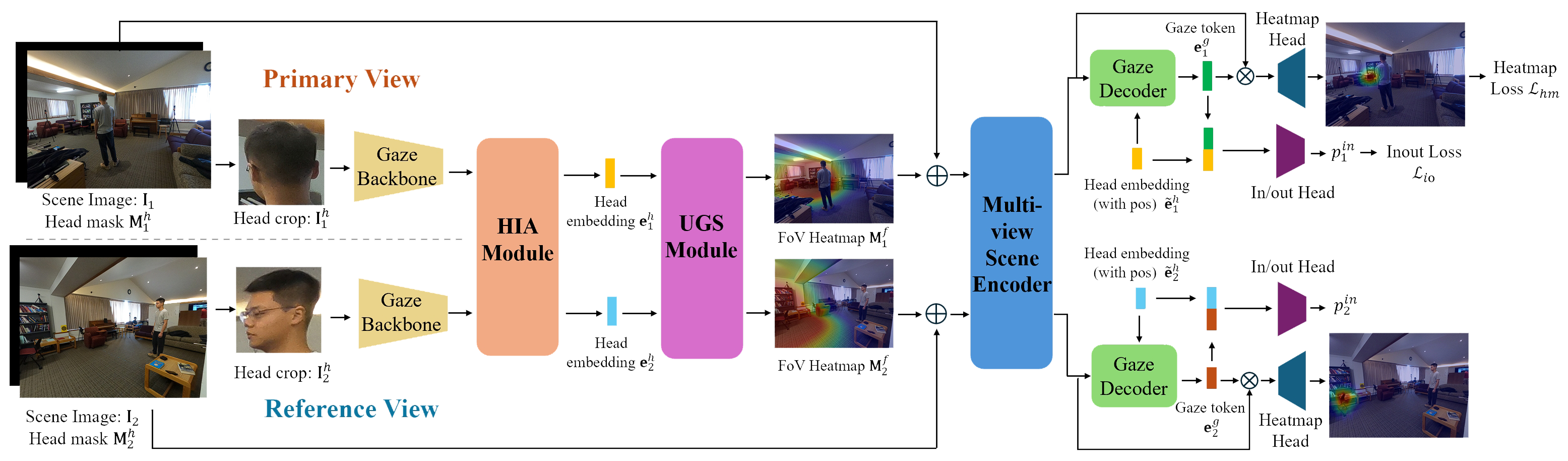

Structures of multi-view processing modules.

Qualitative results for multi-view GTE.
Cross-view GTE
We also introduce a new setting: cross-view GTE, where the gaze target is visible in one view but the person is only visible in the second view. By assuming that more views are available in the reconstruction phase, we manage to estimate the gaze target in the first view with the modified model structure and the reconstructed 3D scene. The 3D reconstruction model is only applied once, and not required in later gaze target estimation.
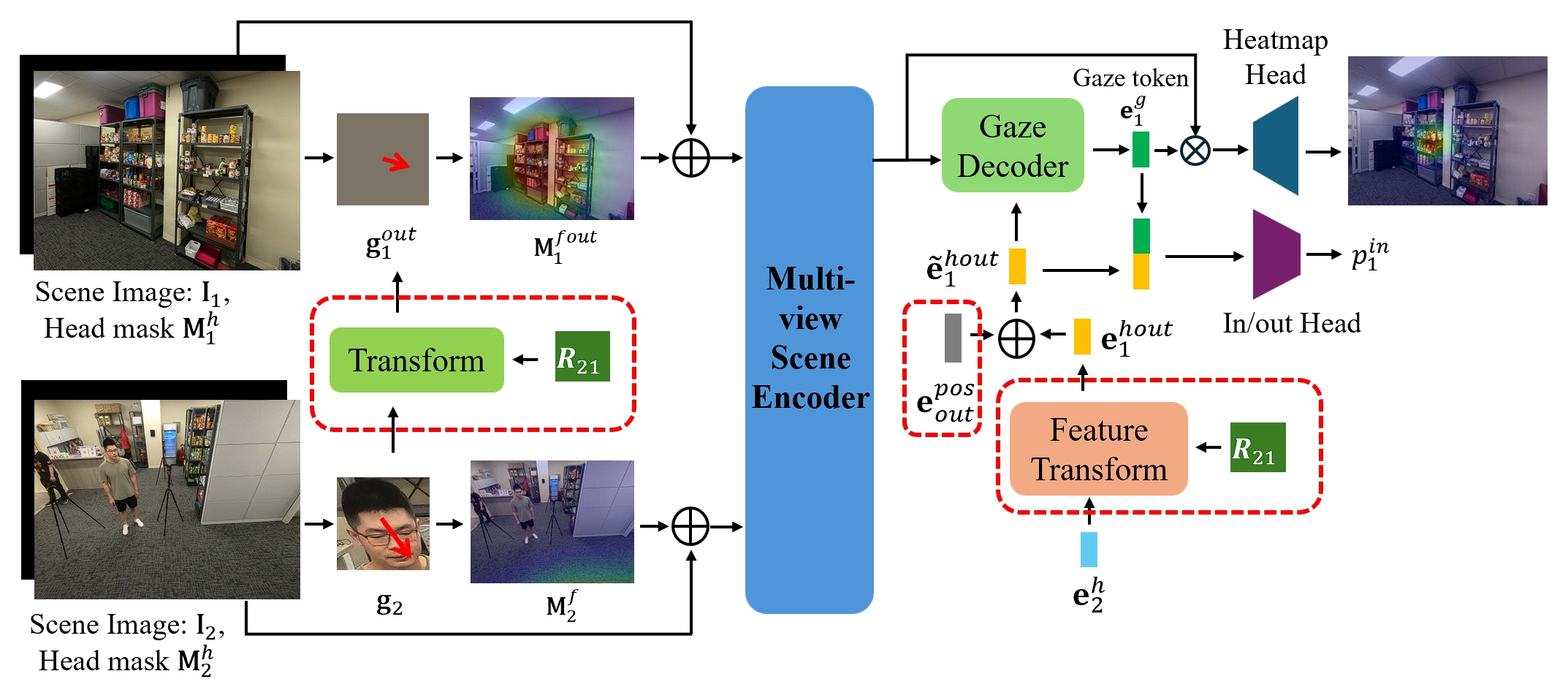
Structure of our cross-view GTE model.

Qualitative results for cross-view GTE.
Acknowledgments
-
This project was partially supported by NSF award IIS-2123920 and the Department of Surgery at Stony Brook University. Minh Hoai was initially supported by NSF award DUE-2055406, and later in part by the Australian Institute for Machine Learning (University of Adelaide) and the Centre for Augmented Reasoning, an initiative of the Australian Government's Department of Education.
The authors thank Haoyu Wu for helpful discussions.