|
|
| F2Dock: |
F2Dock is a multithreaded rigid-body protein-protein docking software written in C++.
It also has an MPI (Message Passing Interface) based distributed implementation,
and a GUI (Graphical User Interface) front-end. F2Dock includes a novel
shape-complementarity function as well as on-the-fly affinity functions
based on electrostatics, hydrophobicity and hydrogen bonds. These
functions are evaluated using uniform FFT (Fast Fourier Transform),
but the sparsity of FFT grids and the search space are exploited in
various ways for faster execution. F2Dock also includes efficient
on-the-fly filters (for eliminating/penalizing potential false positives) based
on Lennard-Jones potential, dispersion energy, steric clashes, hydrophobicity,
residue-residue contact preferences (statistical), and interface area.
The filters are implemented using fast multipole-type
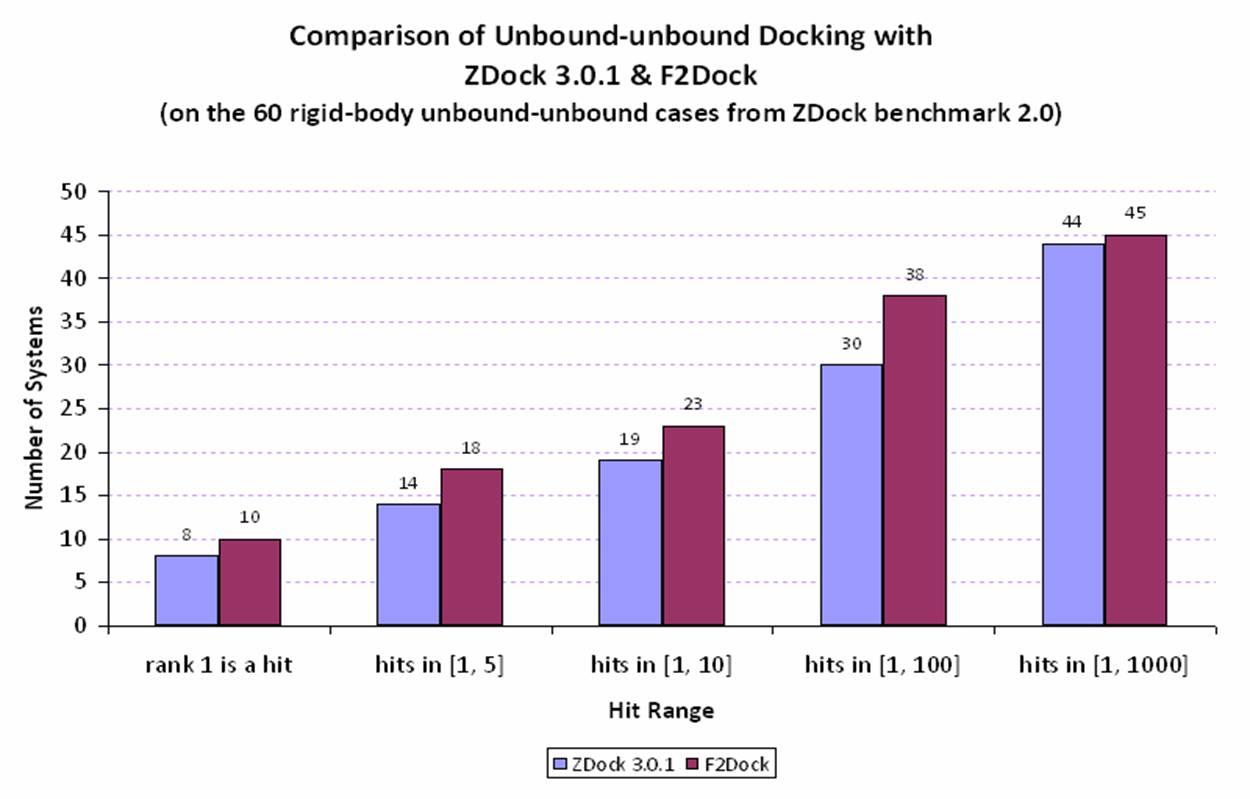
hiearchical (adaptive) spatial decomposition schemes. Here is a quick snapshot of
F2Dock's performance as of July 2010 (F2Dock is
constantly improving).
 For more information please visit:
For more information please visit:
|
| |
F2Dock homepage on CVCWeb
|
|
|
| GB-rerank: |
GB-rerank reranks the docking poses obtained
from an initial-stage docking software (e.g., F2Dock) based on a more
accurate evaluation of the change in solvation energy. The polar part of the solvation
energy is approximated using the surface-based formulation of Generalized Born
(GB) energy, and implemented using a multithreaded fast octree-based approximation
scheme. The non-polar part is approximated
by computing an approximate interface area of the two molecules using our
fast linear-space Dynamic Packing Grid (DPG) data structure,
and an approximate dispersion energy using an octree-based algorithm.
|
|
|
| MolEnergy: |
This package includes multithreaded
fast octree-based approximation schemes for computing Lennard-Jones
potential, electrostatics and solvation energy. It also includes
an NFFT (Non-uniform FFT) based algorithm for computing polarization
energy based on GB (Generalized Born) theory as well as a
BEM (Boundary Element Method) based approach for computing
the same using PB (Poisson-Boltzmann) theory.
|
|
|
| Pochoir: |
Pochoir (pronounced "PO-shwar") is a system for automatically parallelizing
and optimizing stencils. A stencil defines the value of a grid point in a
d-dimensional spatial grid at time t as a function of neighboring
grid points at recent times before t. A stencil computation computes the
stencil repeatedly for each grid point over many time steps. Stencils have
numerous applications, for example, Lattice Boltzmann Method in physics, seismic
imaging, finite difference methods in finances, biosequence analysis, image
enhancements using filters, etc.
In Pochoir one specifies a stencil as a
mathematical formula using the Pochoir stencil specification language, which is
embedded in C++. The Pochoir compiler then produces a highly optimized
parallel code from that simple specification. Pochoir uses a non-trivial
cache-efficient parallel algorithm for stencil computations, and the resulting
code runs 2–10 times faster than straightforward parallel loop code.
For more information please visit:
|
| |
Pochoir homepage at MIT CSAIL
|
|
|
| AutoGen: |
AutoGen is a system that for a wide class of dynamic
programming (DP) problems automatically discovers highly efficient cache-oblivious
parallel recursive divide-and-conquer algorithms from inefficient iterative descriptions
of DP recurrences. AutoGen analyzes the set of DP table locations accessed by the iterative
algorithm when run on a DP table of small size, and automatically identifies a recursive
access pattern and a corresponding provably correct recursive algorithm for solving the
DP recurrence. Empirical results show that several these auto-discovered algorithms significantly
outperform parallel looping and tiled loop-based algorithms. Also these algorithms are
less sensitive to memory and bandwidth fluctuations compared to their looping counterparts,
and their running times and energy profiles remain relatively more stable.
To the best of our knowledge, AutoGen is the first algorithm that can automatically
discover new nontrivial divide-and-conquer algorithms.
|