Thread-safe: recognizing human actions across shot boundaries
Abstract
We study the task of recognizing human actions in the presence of editing effects. In particular, shot boundaries and shot patterns exist in edited TV material, but they are ignored by existing action recognition algorithms. The goal of this research is to develop a novel algorithm that embraces the existence of shot boundaries and shot patterns to improve human action recognition performance.
 |
Figure 1. A typical video sequence. Analyzing edited TV material is challenging due to the existence of shot boundaries. This scene can be divided into shots, and shots can be grouped into threads as illustrated in Figure 2. |
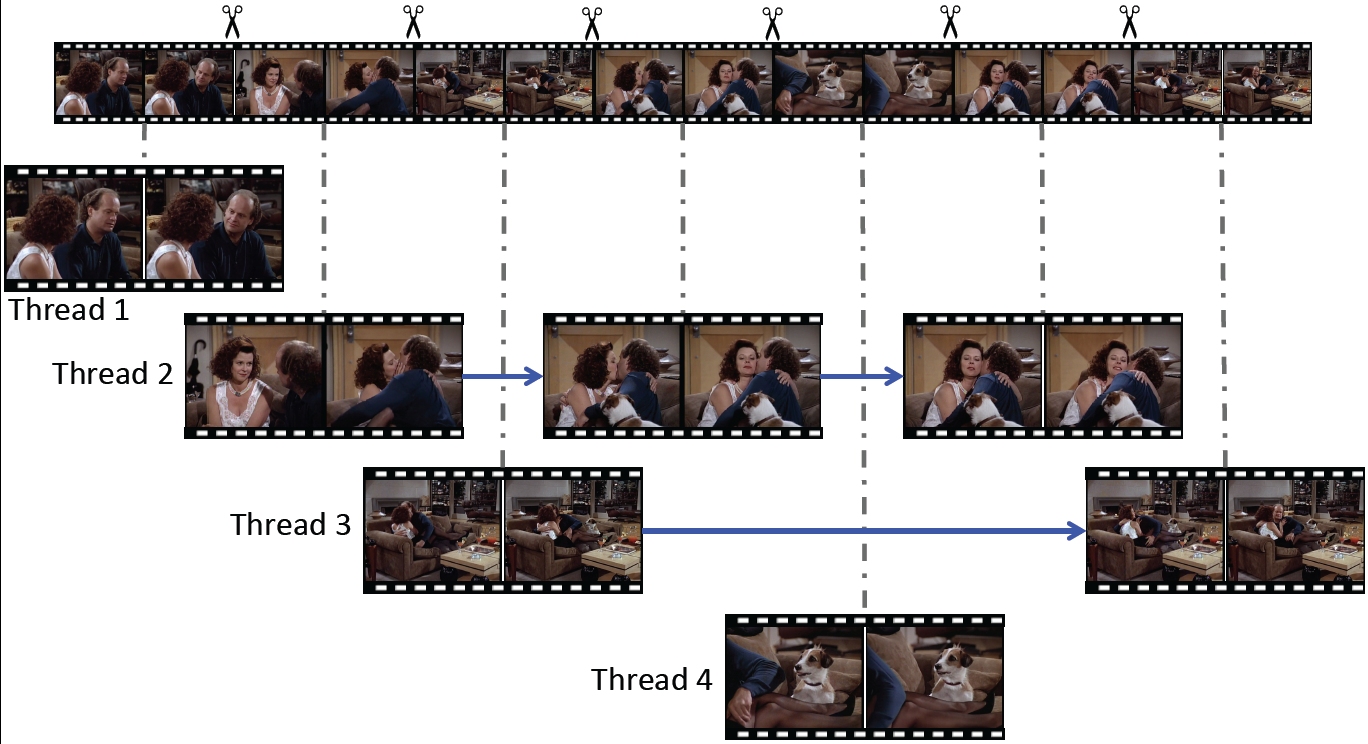 |
Figure 2. Shots and threads. This video sequence of an affectionate kiss consists of several interleaving threads. Thread 1 sets the context for the kiss, while Threads 2 and 3 portray the kiss at different angles. Thread 4 shows a dog being amused by the affection between two people. This thread shows a part of the scene, but it is completely irrelevant to the kissing action.
Overview
To develop a method that can recognize human actions in the presence of editing effects, we will perform the following tasks. First, we will collect a new dataset of human actions that can be used to study the occurrence/reoccurrence patterns of human actions in edited TV material. Second, we will develop an algorithm to decompose a video into threads of related shots, removing the discontinuity due to shot boundaries. Third, we will study the benefits of utilizing video threads in recognizing human actions.
Data collection. Due to the lack detailed annotation and contextual surround (video sequences before and after the actions), existing datasets for human actions cannot be used to study the editing structure and the benefits of using shot patterns for recognition. Therefore we propose to collect a new dataset of human actions.
We aim to extract data from a large collection of DVDs. To obtain rough locations of human actions, we will use video-aligned scripts [1]. By searching video-aligned scripts, we will retrieve video samples for several dozens of human actions that frequently occur in TV shows. We aim to collect ten thousands of those video samples. Each video sample will be divided into shots, and Amazon Mechanical Turk (MTurk) will be used to mark the occurrence of human actions in each shot.
Thread decomposition and thread pattern analysis. We will reverse the editing effect and decompose a video into threads [2]. Each thread is an ordered sequence of shots, filming the same scene by the same camera. Recall that a scene is typically filmed by multiple cameras at multiple angles, and a video is composed by cutting and joining video clips from multiple cameras. These video clips are referred to as shots and the transitions between them are shot boundaries. By constructing threads, we remove abrupt discontinues and obtain uninterrupted portrayals of a scene. This is illustrated in Figure 2.
Once video samples have been decomposed into threads and shot-level annotations have been collected, we can study the temporal extent of human actions over shots and threads. This will help us understand the use of cinematic techniques in filming human actions, and this knowledge would be useful in designing algorithms for human action recognition.
Thread-based human action recognition. We propose to consider threads and develop better algorithms for human action recognition. We believe the benefits of considering threads are twofold. First, threads remove abrupt discontinues due to shot boundaries. Second, threads can be used to exclude parts of a video sequence that are irrelevant to the action of interest, as illustrated in Figure 2.
In addition to verifying the benefits of threads, we propose to develop a weakly supervised learning algorithm [3,4] for automated identification of relevant threads. This algorithm will not require detailed annotation at the shot level; it will train a classifier from video samples annotated only with binary labels indicating the presence of an action of interest. A technical novelty of this algorithm will be the ability to extract video sequences outside the action samples and use these video sequences as hard negative examples.
People
Minh Hoai Nguyen and Andrew Zisserman
References
[1] M. Everingham, J. Sivic, and A. Zisserman. “hello! my name is … Buffy” – automatic naming of characters in TV video. In Proceeding of British Machine Vision Conference, 2006.
[2] T. Cour, C. Jordan, E. Milsakaki, and B. Taskar. Movie/script: Alignment and parsing of video and text transcription. In Proceeding of European Conference on Computer Vision, 2008.
[3] M. H. Nguyen, L. Torresani, F. De la Torre, and C. Rother. Weakly supervised discriminative localization and classification: a joint learning process. In Proceeding of International Conference on Computer Vision, 2009.
[4] M. Hoai, L. Torresani, F. De la Torre, and C. Rother. Learning discriminative localization from weakly labeled data. Pattern Recognition, 47(3):1523–1534, 2014.