
|
|
News Archive |
||
|
Feb 5, 2018: CSIRE Program (2018) for K12 Students at Stony Brook University.
We are excited to announce the
"Computer Science and Informatics
Research Experience Program for K12 Students" (CSIRE) 2018 at Stony Brook University.
The CSIRE program at Stony Brook University is an opportunity for qualified, academically talented and motivated K12 students interested in pursuing a career in Computer Science or Informatics. The program provides the students a unique research experience working with leading researchers in the field.
January 23, 2018: Our summer high student Kavya Kopparapu is named a Finalist in Regeneron Science Talent Search.
Kavya Kopparapu, a summer student in Simons Summer Program of Stony Brook University, mentored by our lab, has been named a top 40 Finalist in the 77th Regeneron Science Talent Search—the nation’s oldest and most prestigious science and mathematics competition for high school seniors. Kavya will travel to Washington, DC in March to participate in the Finals Week competition. Finalists are each awarded at least $25,000, and the top 10 awards range from $40,000 to $250,000. The top 10 Regeneron Science Talent Search 2018 winners will be announced at a black-tie gala awards ceremony at the National Building Museum on March 13, 2018. More information is in the news.
January 22, 2018: I am teaching a new CS course "Introduction to Biomedical Informatics".
I am teaching a new undergraduate CS course CSE393: Introduction to Biomedical Informatics. cover the basis of biomedical informatics, including biomedical and healthcare data management and standards, medical imaging informatics, medical image analysis, bioinfromatics, and public health informatics and GIS.
December 14, 2017: Yanhui Liang successfully defended her Ph.D. dissertation.
Yanhui Liang successfully defended her dissertation on "Integrative Image and Spatial Analytics for Three-Dimensional Digital Pathology". She will join Google Brain. August 29, 2017: We have three full papers accepted to SIGSPATIAL 2017.
iSPEED: an Efficient In-Memory Based Spatial Query System for Large-Scale 3D Data with Complex Structures.
SparkGIS: Resource Aware Efficient In-Memory Spatial Query Processing. Effective Scalable and Integrative Geocoding for Massive Address Datasets. May 31, 2017: CSIRE Program for K12 Students at Stony Brook University.
We are excited to announce that we started a new program "Computer Science and Informatics Research Experience Program for K12 Students" (CSIRE) at Stony Brook University. The CSIRE program at Stony Brook University is an opportunity for qualified, academically talented and motivated K12 students interested in pursuing a career in Computer Science or Informatics. The program provides the students a unique research experience working with leading researchers in the field. January 31, 2017: NSF REU Opening: Exploring Scalable Data Analytics
for Big Data at Stony Brook University.
I am looking for a highly motivated undergraduate student with CS or informatics major to work on an NSF sponsored project on Research Experiences for Undergraduates (REU).
If you are interested, please submit your application at SPIDAL REU at Stony Brook University . January 25, 2017: We are organizing the Third International Workshop on Data Management and Analytics for Medicine and Healthcare (DMAH'2017), in conjunction with VLDB 2017.
The workshop will bring people cross-cutting the fields of information management and medical informatics,
to discuss innovative data management and analytics technologies highlighting end-to-end applications, systems, and methods to
address problems in healthcare, public health, and everyday wellness, with clinical, physiological, imaging, behavioral,
environmental, and omic- data, and data from social media.
The workshop will be held at Munich, Germany on September 1, 2017.
The workshop is in conjunction with the 43rd Very Large Databases Conference (VLDB 2017).

 January 1, 2017: ACM Technews on industrial adoption of our GPU accelrated spatial querying methods.
ACM TechNews
featured our research on GPU accelerated spatial querying methods, which are adopted
byFixstars Solutions Inc
for their geometry compuation engine.
The work (published in VLDB 2012) is in collaboration with the Ohio State University.
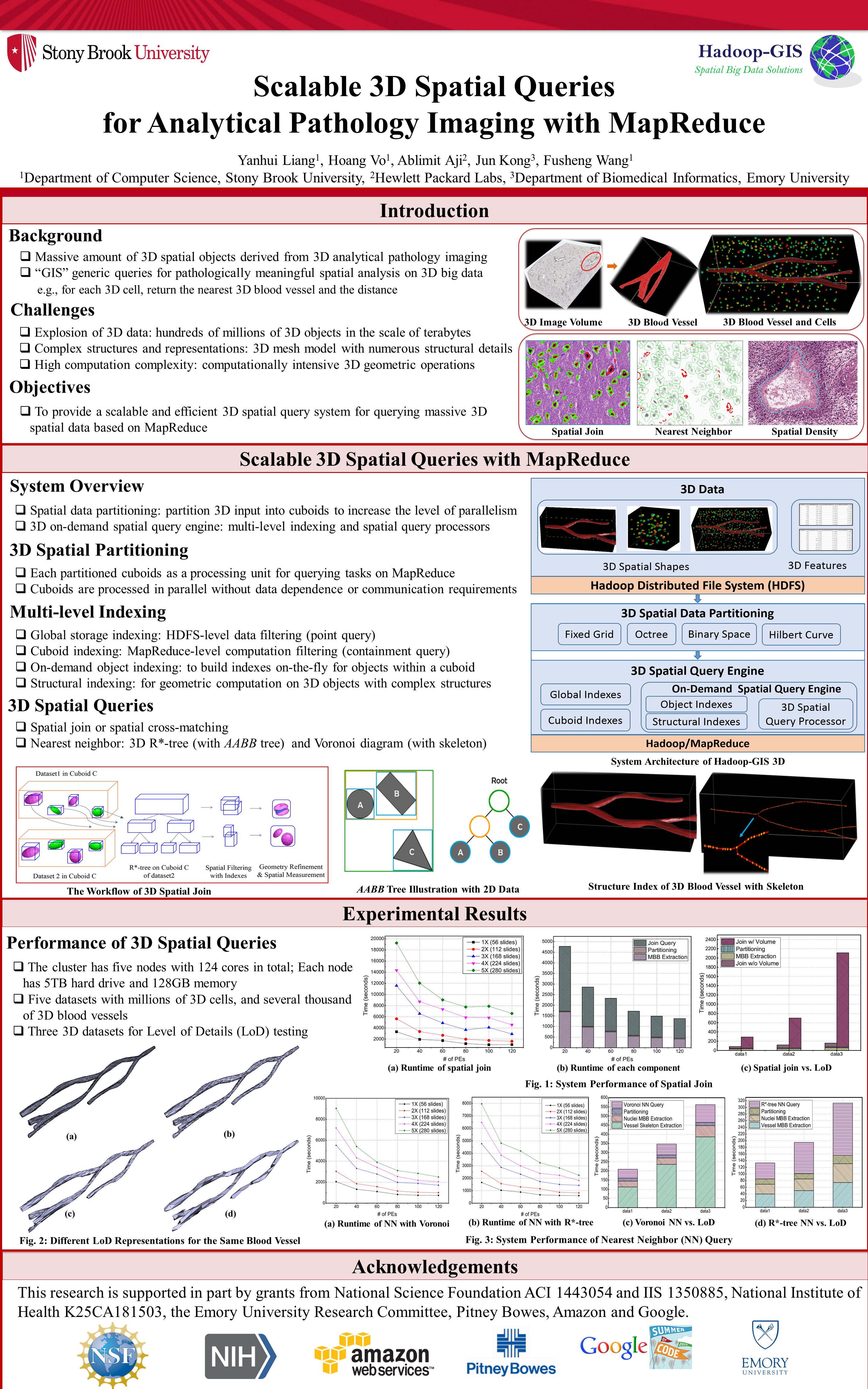
November 2, 2016: Yanhui Liang won the best poster award at SIGSPATIAL 2016.
Yanhui's paper "Scalable 3D Spatial Queries for Analytical Pathology Imaging with MapReduce" won the best poster award at SIGSPATIAL 2016.
 June 10, 2016: I will teach CSE532: Theory of Database Systems this fall.
This course covers recent advances in data management systems. Topics include complex queries and optimizations, XML data management, spatial data management, distributed and parallel databases, NoSQL databases, and MapReduce based data processing systems. We will discuss the foundations of data models, transaction models, storage, indexing and querying methods for these data management systems. We will demonstrate real world databases with biomedical data, geospatial data and/or social media data.
Course Website March 15, 2016: NSF REU Opening: Exploring Scalable Data Analytics
for Big Data at Stony Brook University.
I am looking for a highly motivated undergraduate student with CS or informatics major to work on an NSF sponsored project on Research Experiences for Undergraduates (REU).
If you are interested, please submit your application at SPIDAL REU at Stony Brook University . March 1, 2016: We are organizing the Second International Workshop on Data Management and Analytics for Medicine and Healthcare (DMAH'2016), in conjunction with VLDB 2016.
The workshop will bring people cross-cutting the fields of information management and medical informatics,
to discuss innovative data management and analytics technologies highlighting end-to-end applications, systems, and methods to
address problems in healthcare, public health, and everyday wellness, with clinical, physiological, imaging, behavioral,
environmental, and omic- data, and data from social media.
The workshop will be held at New Delhi, India on September 9, 2016.
The workshop is in conjunction with the Very Large Databases Conference (VLDB).
 Febrary 28, 2016: Department of Biomedical Inforamtics is selected again by Google as a Google Summer of Code Organization.
Google Summer of Code is a global program focused on introducing students to open source software development. Students work on a 3 month programming project with an open source organization during their break from university.
The Department of Biomedical Informatics (organization administrator: Fusheng Wang) of Stony Brook University is selected one of the
open source organizations to provide projects for students.
December 23, 2015: We won EDBT 2016 Test of Time Award.
Our paper "Bridging Physical and Virtual Worlds: Complex Event Processing for RFID Data Streams"
is selected for the EDBT 2016 Test of Time Award. The International Conference on Extending Database Technology (EDBT) is a premium
conference on database technologies. The conference awards the EDBT test-of-time (ToT) award, with the goal of recognizing one paper,
or a small number of papers, presented at EDBT earlier and that have best met the "test of time", i.e. that has had the most impact in terms of research, methodology, conceptual contribution, or transfer to practice over the past decade(s).
 EDBT Test of Time Awards September 28, 2015: Shuai Zheng joined Centers for Disease Control and Prevention.
Shuai Zheng successfully defended his Ph.D. thesis "Online Learning Based Clinical Information Extraction and Classification" and joined Centers for Disease Control and Prevention.
April 14, 2015: I will teach CSE532: Theory of Database Systems this fall.
April 2, 2015: We are awarded an Amazon AWS Teaching Grant.
March 26, 2015: NSF REU Opening: Exploring Scalable Data Analytics
for Big Data at Stony Brook University.
I am looking for highly motivated undergraduate student with CS or informatics major to work on an NSF sponsored project on Research Experiences for Undergraduates (REU).
If you are interested, please submit your application at SPIDAL REU at Stony Brook University . http://technews.acm.org/archives.cfm?searchterm=Chromium&fo=2017-01-jan%2Fjan-04-2017.html#903816 January 31, 2015: We are organizing the First International Workshop on Data Management and Analytics for Medicine and Healthcare (DMAH'2015), in conjunction with VLDB 2015.
The workshop will bring people cross-cutting the fields of information management and medical informatics,
to discuss innovative data management and analytics technologies highlighting end-to-end applications, systems, and methods to
address problems in healthcare, public health, and everyday wellness, with clinical, physiological, imaging, behavioral,
environmental, and omic- data, and data from social media.
The workshop will be held at the Big Island of Hawaii on September 5, 2015.
The workshop is in conjunction with the Very Large Databases Conference (VLDB).
 Download the brochure. January 8, 2015: I joined Stony Brook University.
I moved to Stony Brook University for a joint appointment at
Department of Biomedical Informatics and Department of Computer Science, starting in January, 2015.
October 31, 2014: Congratulations to Ablimit Aji on successfully defending his Ph.D. thesis!
Ablimit Aji has defended his Ph.D. thesis, and is now Dr. Aji. His disseration title is "High Performance Spatial Query Processing for Large Scale Spatial Data Warehousing".
He is currently a research scientist at HP Labs. Group picture. September 7, 2014: We are awarded an NSF ACI Award on "CIF21 DIBBs: Middleware and High Performance Analytics Libraries for Scalable Data Science".
We are awarded a $5M from NSF on CIF21 DIBBs: Middleware and High Performance Analytics Libraries for Scalable Data Science".
The project will design and implement a software Middleware for Data-Intensive Analytics and
Science (MIDAS) that will enable scalable applications with the performance of HPC
(High Performance Computing) and the rich functionality of the commodity Apache Big Data Stack.
Further, this project will design and implement a set of cross-cutting high-performance data-analysis
libraries, which will support new programming and execution models for data-intensive analysis in a
wide range of science and engineering applications.
NSF Press Release: Laying the Groundwork for Data-driven Science August 20, 2014: NSF CAREER award.
I am awarded an NSF CAREER award on High Performance Spatial Queries and Analytics for Spatial Big Data", to build next generation spatial big data system.
Emory News Release: Computer scientist receives NSF CAREER award to develop software for spatial big data August 14, 2014: We are awarded an Amazon AWS in Education Research grant.
We are awarded an Amazon AWS in Educaiton Research Grant for building Cloud Enabled Pathology Image Analytics Software.
AWS in Education Research Grants July 10, 2014: We are funded by Center for Disease Control and Prevention for Clinical Natural Language Processing.
We are funded by Center for Disease Control and Prevention (CDC) for a project "Adaptive Self Learning Technology and Surveillance of Venous Thromboembolism through Electronic Health Records".
The project will use natural language processing technologies for extracting and integrating clinical data records for VTE surveillance study.
April 1, 2014: Winner of 2014 IBM Champion.
Recognized as a 2014 IBM Champion of the IBM Champion program. This program recognizes individuals who make significant contributions to IBM communities by advocating the solutions; sharing their knowledge and expertise; and helping nurture and grow independent communities.
April 18, 2014: A virtual machine version of PAIS system is available for download.
You can now install PAIS from the VM release.You can follow the instructions
to setup.
March 28, 2014: Ablimit joined HP Labs.
Farewell lunch picture.
December 12, 2013: Hadoop-GIS is available in Amazon Elastic MapReduce.
We have provided a library for Hahoop-GIS to run on Amazon Elastic MapReduce (EMR).You can follow the instructions to quickly start running your
large scale spatial queries on Amazon cloud.
September 24, 2013: PAIS Portal demo is available.
We have a demo pathology analytical imaging portal ready. You can browse, download, visualize images and anaytical results.
August 28, 2013: Hadoop-GIS 1.0 alpha released.
Hadoop-GIS 1.0 alpha is released. Please find the source code at https://github.com/hadoop-gis. A demo will be presented at SIGSpatial GIS Conference at Orlando, November 5-8, 2013.
We are also looking for community contributors. A Hive feature request has been submitted at Hive JIRA.
July 4, 2013: Our work on adaptive learning based approach for clinical information extraction is accepted to AMIA Annual Symposium, 2013.
Our paper "ASLForm: An Adaptive Self Learning Medical Form Generating System" is accepted to AMIA Annual Symposium, Washington, DC, November 16-20, 2013.
ASLForm is an interactive, incrementally learning based system data extraction system for clinical narrative reports.
ASLForm provides users a convenient interface that can be used as a simple data extraction and data entry system. User feedback can incrementally refine the decision model in real-time,
which further reduces users' interaction effort thereafter. The system eventually achieves high accuracy on data extraction with minimal effort from users.
You can watch a demo video here. June 1, 2013: Our paper entitled "
Our paper entitled "Hadoop-GIS: A High Performance Spatial Data Warehousing System Over MapReduce" is accepted to the 39th International Conference on Very Large Databases (VLDB'2013), Trento, Italy, August 26-30, 2013.
Hadoop-GIS is a scalable and high performance spatial data warehousing system for running large scale spatial queries on Hadoop. Hadoop-GIS supports multiple types of spatial queries on MapReduce through space partitioning, customizable spatial query engine RESQUE, implicit parallel spatial query execution on MapReduce, and effective methods for amending query results through handling boundary objects on MapReduce. Hadoop-GIS takes advantage of global partition indexing and customizable
on demand local spatial indexing to achieve efficient query processing. Hadoop-GIS is integrated into Hive to support declarative spatial queries with an integrated architecture.
May 10, 2013: Winner of 2013 IBM Champion.
Recognized as a 2013 IBM Champion of the IBM Champion program. This program recognizes individuals who make significant contributions to IBM communities by advocating the solutions; sharing their knowledge and expertise; and helping nurture and grow independent communities.
June 1, 2013: Our paper entitled "Hadoop-GIS: A Spatial Data Warehousing System Over MapReduce" is accepted to VLDB 2013.
Our paper entitled "Hadoop-GIS: A Spatial Data Warehousing System Over MapReduce" is accepted to The 39th International Conference on Very Large Databases (VLDB'2013), Trento, Italy, August 26-30, 2013.
Hadoop-GIS is a scalable and high performance spatial data warehousing system for running large scale spatial queries on Hadoop. Hadoop-GIS supports multiple types of spatial queries on MapReduce through space partitioning, customizable spatial query engine RESQUE, implicit parallel spatial query execution on MapReduce, and effective methods for amending query results through handling boundary objects on MapReduce. Hadoop-GIS takes advantage of global partition indexing and customizable
on demand local spatial indexing to achieve efficient query processing. Hadoop-GIS is integrated into Hive to support declarative spatial queries with an integrated architecture.
May 10, 2013: Winner of 2013 IBM Champion.
Recognized as a 2013 IBM Champion of the IBM Champion program. This program recognizes individuals who make significant contributions to IBM communities by advocating the solutions; sharing their knowledge and expertise; and helping nurture and grow independent communities.
April 25, 2013: We are organizing the Fifth International Workshop on Cloud Data Management (CloudDB 2013), in conjunction with CIKM 2013.
The Fifth International workshop on Cloud Data Management (CloudDB 2013) will bring together researchers and practitioners in cloud computing and data-intensive system design, programming, parallel algorithms, data management, scientific applications, and information-based applications to maximize performance, minimize cost and improve the scale of their endeavours.
April 19, 2013: Our temporal colaescing method is adopted by Teradata Temporal.
Teradata offers native support to a wide range of temporal analytics. Temporal coalescing is a key temporal
query processing operation, and we developed an orderd analytical funciton based approach to support temporal coalescing, which
is adopted by Teradata for its temporal database support.
October 12, 2012: We won the best presentation award at Pathology Informatics Conference 2012.
Our talk "MIGIS: High Performance Spatial Query System for Analytical Pathology Imaging" won the best presentation award of the session of Pathology Informatics Conference, Chicago, October 9-12, 2012. Pathology Informatics is a subdiscipline of pathology and clinical laboratory medicine, and the annual conference is the largest meeting with a broad attedance of experts in the fields of pathology and informatics.
May 10, 2012: We are organizing the Fourth International Workshop on Cloud Data Management (CloudDB 2012), in conjunction with CIKM 2012.
The Fourth International workshop on Cloud Data Management (CloudDB 2012) will bring together researchers and practitioners in cloud computing and data-intensive system design, programming, parallel algorithms, data management, scientific applications, and information-based applications to maximize performance, minimize cost and improve the scale of their endeavours.
May 3, 2012: Our paper on "Accelerating Pathology Image Data Cross Comparison on CPU-GPU Hybrid Systems" is accepted to VLDB 2012.
Our paper on building hybrid CPU-GPU based solution for spatially cross-matching of pathology image data is accepted to the Very Large Data Base Conference (VLDB'2012).
The work is in collaboration with Ohio State University.
January 31, 2012: We are organizing the Extremely Large Databases Asia (XLDB Asia) Conference at Beijing this summer (June 22-23, 2012).
The Extremely Large Databases (XLDB) series of conferences/workshops (xldb.org) have been held successfully with the leadership of Jacek Becla in recent years. The first XLDB satellite conference in Asia (XLDB Asia) will be held at Beijing, China on June 22-23, 2012.
This conference will bring together people with highly demanding data challenges, and researchers and solution providers who are developing systems to address such challenges.
The conference will facilitate discussions on:
Practical use cases of current and anticipated data challenges; Lessons and innovations on building extremely large databases; Trends and strategies for surmounting current hurdles. 
December 8, 2011: AWS in Education research grant award.
We have been selected to receive an Amazon AWS in Education research grant (two years).
July 20, 2011: Dr. Wang was elected as a SPIE Senior Member, among 28 new senior members honored this year.
Dr. Wang was elected by the Society of Photographic Instrumentation Engineers (SPIE) Board of Directors and the Membership Committee to the grade of Senior Member, among 28 new senior members honored this year from 16,000 members, for his achievements in data management, integration and standardization for medical images and RFID. SPIE Senior Members are Members of distinction who are honored for their professional experience, their active involvement with the optics community and SPIE, and/or significant performance that sets them apart from their peers. See list of 2011 SPIE Senior Members.
June 24, 2011: Best Paper Award Received at ICDCS 2011.
The 31st International Conference on Distributed Computing Systems (ICDCS 11) presented the Best Paper Award to the researchers at Ohio State University (Rubao Lee, Tian Luo, Yin Hua, Xiaodong Zhang), Emory University(Fusheng Wang), and Facebook (Yongqiang He)to their paper entitled "YSmart: Yet another SQL-to-MapReduce Translator."
MapReduce has become a standard software framework for big data analytics in distributed systems, where system execution of SQL queries is a critical data processing task. An SQL-to-MapReduce translator automatically converts database queries to MapReduce jobs for their execution in distributed systems. Complex SQL query jobs generated by existing translators, such as the one in data warehouse Hive developed in Facebook, and in MapReduce programming environment of Pig developed by Yahoo!, are executed at unacceptable slow speed. The authors of the paper demonstrate that the poor performance of these translators is caused by the framework of one-operation-to-one-job mapping, which does not consider correlations of input data and input keys among the queries. The authors design and implement a correlation-aware SQL-to-MapReduce translator, called YSmart. The translator achieves superior performance compared with the existing translators in Hive and Pig. The translator has been patched in Hive for an adoption, and an independent version of YSmart will be released for public usage.
ICDCS is an annual conference providing a forum for engineers and scientists in academia, industry and government to present their latest research findings in many aspects of distributed and parallel computing. The annual conference this year was held in Minneapolis, Minnesota, June 21-24, 2011.
September 20, 2010: Dr. Wang won the best presentation award at Pathology Informatics Conference 2010.
Dr. Wang's talk "Developing Data Model Standards and Databases for Pathology Analytical Imaging" won the best presentation award of the session of Pathology Informatics Conference, Boston, September 19-22, 2010. Pathology Informatics is a subdiscipline of pathology and clinical laboratory medicine, and the annual conference is the largest meeting with a broad attedance of experts in the field of pathology and informatics.
|